



不管是在传统应用时代,还是现在的微服务时代, 应用的稳定性,健壮性,可用性,服务质量等都是任何应用系统都要考虑的问题。 在应用提供服务的时候,会因为很多原因导致应用的韧性遇到各种挑战,举例来说,如各种硬件问题,各种网络问题、内核问题、架构问题、外部依赖、突发流量等等。特别是在微服务时代,应 用的复杂度不断 地 增大。在这种情况下,除了常见的可观测性和可运维性, 有没有一些其它方式来提前发现问题?也许混沌工程就是答案之一。
那什么是混沌工程,混沌工程是一种方法论。通俗理解,以应用为出发点,在各种环境和条件下,给应用系统注入各种可预测的故障,以此来验证应用在面对各种故障发生的时候,它的服务质量和稳定性等能力。在真正开始之前,我们需要分析系统的设计和形态,需要做到故障场景的识别和定义,以此作为依据来建立故障库,最后完成故障演练沙盘的建设。
目前 CNCF 社区在围绕云原生体系来定义和建设云原生时代的混沌工程的具体实现方案,当前在 CNCF 的开源项目有三个,包括 Chaos Mesh、Litmus、Chaos Blade,还有一些非CNCF生态的开源项目,如 Netflix 公司著名的 Chaos Monkey 等。 这里具体以 Chaos Mesh 为切入点来分析分析云原生时代的混沌工程的一些玩法和设计。
01、混沌工程的五大基本原则
建立服务稳定状态的假设: 通过技术指标和业务指标,定义出一组指标,这组指标可以代表服务的稳定状态。
多样化真实世界的事件: 尽可能的归纳出需要模拟的一些故障,而且这些故障是性价比很高的故障类型。对于模拟成本非常高的,而且意义不大的故障,这类型的事件模拟是性价比很低的。
在生产环境中进行实验: 为什么要在生产环境中实验,因为对外服务的系统是生产环境的系统,所以真正的生产环境的服务需要有韧性, 在 生产环境的服务具备弹性和可快速恢复性的情况下,才可以使用混沌工程进行实验,不断的提高生产环境的服务的韧性。
持续地进行自动化实验: 混沌实验需要常态化的运行,为了减少实验成本,需要有自动化实验的能力,以此来持续化的进行实验,不断的发现问题和优化服务。
最小化爆炸半径(最小化影响范围): 服务的第一要求就是对用户的使用体验要好,不能为了实验而影响客户的正常使用。所以需要定义和识别出可操作,有意义的实验范围,如选择小部分用户,选中小范围的服务,进行对应的故障注入,来验证服务的韧性,以避免实验的不可控因素所带来的影响。
02、 术语
混沌工程: 通俗 一点来理解就是为了提高系统的稳定性,以主动的方式设计一些需要的故障点,在这些故障点中注入相关故障,以此来验证,当出现故障的时候系统的表现。
故障(Fault): 在 IT 的世界里,故障应该说是非常常见的。只要是不正常的情况,都可以理解成是故障。举例来说,磁盘坏了、网线断了、机房断电、光纤被挖断、DDOS、DNS 服务出问题、机器的负载很高、依赖的服务下线、应用单点部署、网络延迟大、数据丢包、IO 高负载、应用的 CPU高负载、应用的内存 OOM 等等。
故障注入: 其实就是模拟出故障的过程。如模拟内存压力,就可以启动一个进程不断的消耗内存,以此达到内存有压力的这个效果。
故障恢复: 恢复指的就是取消之前注入的故障,也就是和注入的过程是相反的操作,让其被注入故障的服务,恢复到没有注入故障之前的状态。
实验(Experiment): 从某种意义上来说,也可以理解成是故障注入,但是在混沌工程中,实验更具有抽象性。实验可以理解成,就是对一些事物做一些尝试性的操作,看看最后会发生什么。不管是对什么样的事物,进行什么样的操作,都是属于一种实验而已。所以就会有很多种实验类型。每种实验类型都是围绕给一些事物去模拟一些故障。举例 PodChaos、NetworkChaos、IOChaos、DNSChaos、KernelChaos、JVMChaos 等等,每一种 Chaos 类型,就是一种故障的注入场景。
实验范围(Selector): 在实验的过程中,就需要知道实验对象的是什么。简单理解就是故障点被注入的对象。举例来说,如果想看看某一个 Pod 被删除了,对整个系统的影响。那这个 Pod 就是目标。记录(Record)指的是在实验范围选中的目标中的其中一个目标。在实验执行的过程中,以record 为最小的处理单位来完成故障注入。这个记录的概念是和 Chaos Mesh 本身的实现相关。
混沌工作流(Workflow): 在一些简单的故障场景中,可能只需要一次故障注入就可以了,但是在一些稍微复杂一点的场景中,可能需要在不同的时间段,不同的方式去注入不同的故障来以此模拟一些真实环境中类似的场景。举例来说,对于有状态服务,特别是存储要求比较高的有状态服务,独立的进行存储 IO 的故障注入,然后观察其运行状态是有意义的,那这种就不需要复杂的流水线来编排。对于有一些复杂的微服务系统,在高并发的场景下,如果其中一个微服务出现问题了,那整个系统的表现是什么样的,这种场景是稍微复杂一点的,就可以借助混沌工作流的能力来编排不同的微服务或者模块,以顺序或者并行等其它方式来执行故障注入,来检验系统的稳定性。
计划(Schedule): 简单理解就是定时任务,只是这个被定时的任务都是混沌实验。可以定时运行单个混沌实验,也可以定时运行一个混沌流水线。让其变动的自动化一点,可以很大程度上减少混沌工程带来的操作成本。
事件(Event): 在整个系统中,各种业务处理的过程中的相关状态和问题都会以事件的方式保存下来。类似于 Kubernetes 中子源对象的 Events。方便更便捷的方式查看各种操作的状态和错误的原因。
阶段(Phase): 在 Chaos Mesh 中,根据实验的执行流程,一个混沌实验的生命周期主要分为以下四个阶段: 注入阶段: 混沌实验正在进行注入故障操作。通常情况下,此阶段持续的时间很短。如果此阶段持续的时间很长,可能是由于混沌实验出现了异常,此时可以查看事件信息确定异常原因。 运行阶段: 当所有测试目标都已经被成功注入故障后,混沌实验进入运行阶段。 暂停阶段: 当对混沌实验进行暂停操作时,Chaos Mesh 会恢复所有测试目标,此时实验进入暂停阶段。 结束阶段: 如果配置了实验持续时间,当实验运行时间达到了持续时间后,Chaos Mesh 会恢复所有测试目标,表示实验已经结束。
03、 模型
由于模型有很多,这里以 PodChaos(实验),Schedule(计划),Workflow(工作流),StatusCheck(状态检查)这几种比较有代表性的模型为例,介绍 Chaos Mesh 的常见模型,来帮助理解 Chaos Mesh。
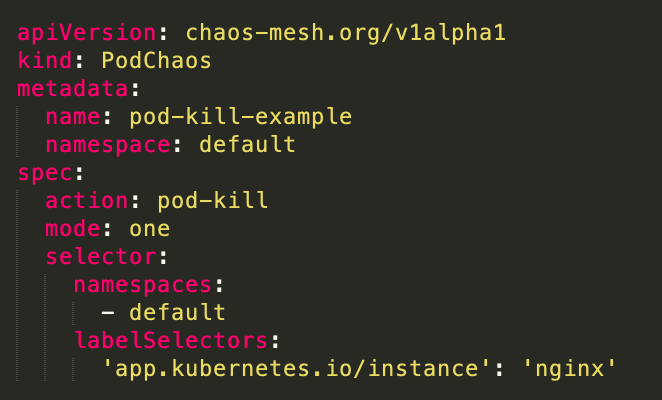
PodChaos: 此例子是在 default namespace 中,选择 lable是 “app.kubernetes.io/instance”: “nginx” 的 Pod,进行模拟删除操作。
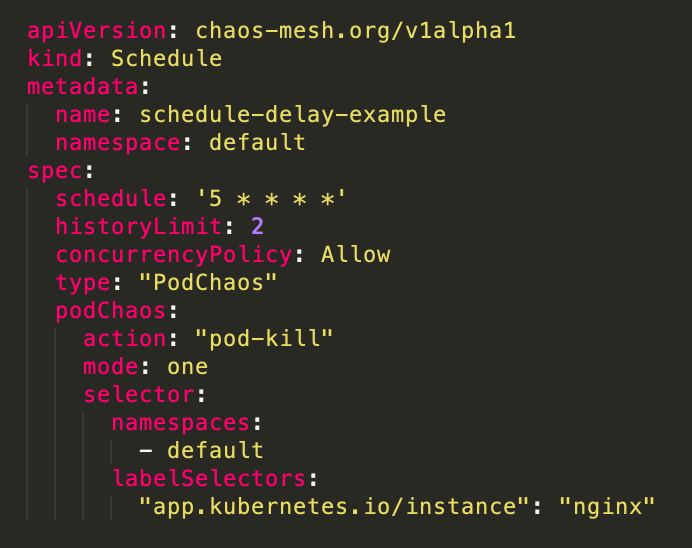
Schedule: 此例子是针对上面的 PodChaos,设置定时执行 PodChaos 的操作,也就是定时删除选中的 Pod。这里关键的字段是 spec.schedule,是用来设置定制的策略。上例的效果是,Chaos Mesh 将会在每个小时的第五分钟(比如 0:05, 1:05…)删除选中的 Pod。
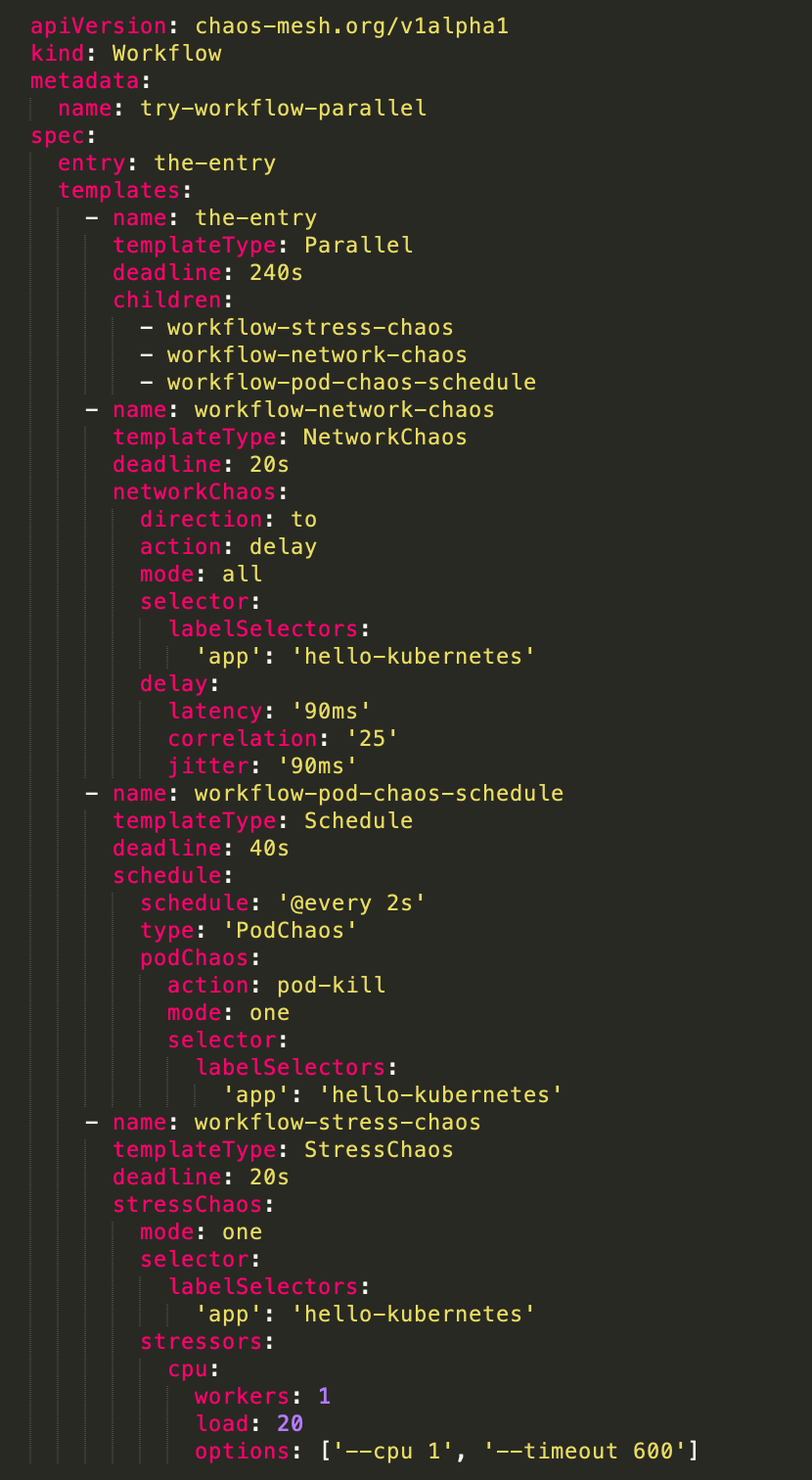
Workflow: 编排各种 chaos 类型的任务,每一个 chaos 对象都是其工作流的一个节点,按照定义的执行策略进行执行,也就是创建对应的 chaos 资源对象。
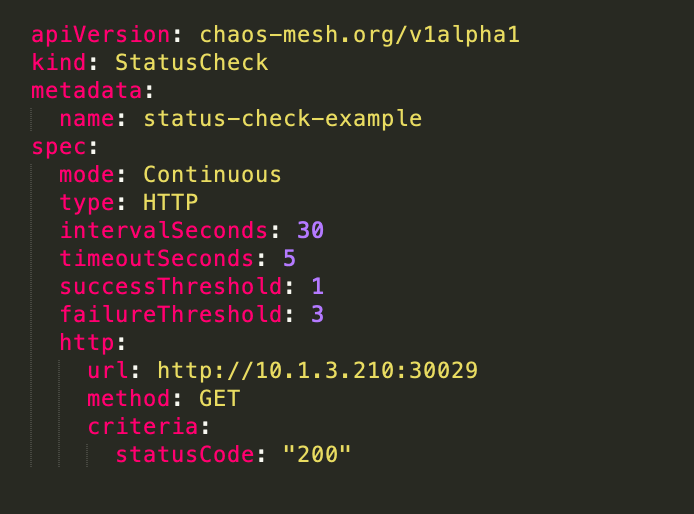
StatusCheck: 支持以 Continuous(持续检查)和 Synchronous(一次性检查)的方式对 http 类型的服务进行状态的检查。
04、 能力
NetworkChaos: NetworkChaos 用于模拟集群中网络故障的场景,目前支持以下几种类型:
-
Partition: 网络断开、分区。
-
NetEmulation: 用于模拟网络状态不良的情况,比如高延迟、高丢包率、包乱序等情况。
-
Bandwidth: 用于限制节点之间通信的带宽。
PodChaos: PodChaos 是 Chaos Mesh 中的一种故障类型,通过创建 PodChaos 类型的混沌实验,你可以模拟指定 Pod 或者容器发生故障的情景。目前,PodChaos 支持模拟以下故障类型:
-
PodFailure: 向指定的 Pod 中注入故障,通过修改Pod的镜像为不可用镜像,使得该 Pod 在一段时间内处于不可用的状态。
-
PodKill: 删除指定的 Pod 。为了保证 Pod 能够成功重启,需要配置 ReplicaSet 或者类似的机制。
-
ContainerKill: 杀死位于目标 Pod 中的指定容器。
IOChaos: IOChaos 是 Chaos Mesh 中的一种故障类型。通过创建 IOChaos 类型的混沌实验,你可以模拟文件系统发生故障的情景。目前,IOChaos 支持模拟以下故障类型:
- latency: 为文件系统调用加入延迟。
- fault: 使文件系统调用返回错误。
- attrOverride: 修改文件属性。
- mistake: 使文件读到或写入错误的值。
StressChaos: 使用在容器中启动新的进程,来模拟 CPU 的高负载和内存的压力,从这两个方面上来模拟压力的效果。
- CPUStressor: 在容器中运行多少个线程来,将 cpu 使用占比,提升到多少百分比。
- MemoryStressor: 在容器中运行多少个线程,来将内存使用占比,提升到总内存的多少百分比。
DNSChaos: DNSChaos 可以用于模拟错误的 DNS 响应,例如在收到 DNS 请求时返回错误,或者返回随机的 IP 地址。
TimeChaos: TimeChaos 实验类型可用于模拟时间偏移的场景。
KernelChaos: KernelChaos 模拟 Linux 内核故障。该功能通过使用 BPF 在指定内核路径上注入基于 I/O 或内存的故障。
HttpChaos: HTTPChaos 是 Chaos Mesh 中的一种故障类型。通过创建 HTTPChaos 实验,你可以模拟 HTTP 服务端在请求或响应过程中发生故障的场景。目前,HTTPChaos 支持模拟以下故障类型:
- abort: 中断服务端的连接。
- delay: 为目标过程注入延迟。
- replace: 替换请求报文或者响应报文的部分内容。
- patch: 给请求报文或响应报文添加额外内容。
JVMChaos: JVMChaos通过 Byteman 模拟 JVM 应用故障,主要支持以下类型的故障:
- 抛出自定义异常。
- 触发垃圾回收。
- 增加方法延迟。
- 指定方法返回值。
- 设置 Byteman 配置文件触发故障。
- 增加 JVM 压力。
AWSChaos: AWSChaos 能够帮助你模拟指定的 AWS 实例发生故障的情景。目前,AWSChaos 支持以下类型的故障:
- EC2Stop: 使指定的 EC2 实例进入停止状态。
- EC2Restart: 重启指定的 EC2 实例。
- DetachVolume: 从指定的 EC2 实例中卸载存储卷。
GCPChaos: GCPChaos 能够帮助你模拟指定的 GCP 实例发生故障的情景。目前,GCPChaos 支持模拟以下故障类型:
- NodeStop: 使指定的 GCP 实例进入停止状态。
- NodeReset: 重置指定的 GCP 实例。
- DiskLoss: 从指定的 GCP 实例中卸载存储卷。
AzureChaos: AWSChaos 能够帮助你模拟指定的 AWS 实例发生故障的情景。目前,AWSChaos 支持以下类型的故障:
- EC2 Stop: 使指定的 EC2 实例进入停止状态。
- EC2Restart: 重启指定的 EC2 实例。
- DetachVolume: 从指定的 EC2 实例中卸载存储卷。
物理机Chaos: Chaosd 是 Chaos Mesh 提供的一款混沌工程测试工具(需要单独下载和部署),用于在物理机环境上注入故障,并提供故障恢复功能。支持故障类型:
- 进程: 对进程进行故障注入,支持进程的 kill、stop 等操作。
- 网络: 对物理机的网络进行故障注入,支持增加网络延迟、丢包、损坏包等操作。
- 压力: 对物理机的 CPU 或内存注入压力。
- 磁盘: 对物理机的磁盘进行故障注入,支持增加读写磁盘负载、填充磁盘等操作。
- 主机** : ** 对物理机本身进行故障注入,支持关机等操作。
RemoteChaos: 在 Chaos Mesh 已经开始实现多集群的场景下的 chaos 能力。目前主要的做法分为管理集群和远程集群,当创建一个 RemoteCluster 的时候,会在这个远程的集群中,通过 Helm 安装 Chaos Mesh,同时为这个远程集群启动一个 controller manager,这个 controller manager 的作用主要是根据控制集群中创建的chaos 资源对象的元数据信息,在远处的集群中同步的创建 chaos 资源对象。目前多集群能力的 chaos 还在持续的开发中,后续可以持续关注。
计划Schedule: 在 Chaos Mesh 中创建定时任务,从而在固定的时间(或根据固定的时间间隔)自动新建混沌实验,具体新建什么混沌实验,就看 Schedule 中定义的 Chaos 类型以及对应的配置。定时的规则可以参考 crontab。
工作流Workflow: Chaos Mesh 提供了 Chaos Mesh 工作流,一个内置的工作流引擎。使用该引擎,你可以串行或并行地执行多种不同的 Chaos 实验, 用于模拟生产级别的错误。目前, Chaos Mesh 工作流支持以下功能:
- 串行编排: 在工作流中的节点,每次只有一个在执行,按照顺序一个一个的执行。
- 并行编排: 在工作流中的节点,所有的节点都是一起执行。
- 自定义任务: 除了内置的各种资源对象,也可以通过自定义的任务,在容器中执行指定的命令。
- 条件分支: 支持根据 Task 的执行结果来选择接下来要执行的节点。
状态检查StatusCheck: 支持以 Continuous(持续检查)和Synchronous(一次性检查)的方式对服务进行状态的检查,目前支持 http 类型的检查。主要能力包括:
- failureThreshold(失败阈值): 当出现连续的失败 “执行结果” 次数超过失败阈值时,则认为 “状态检查结果” 为失败。
- successThreshold(成功阈值): 当出现连续的成功 “执行结果” 次数超过成功阈值时,则认为 “状态检查结果” 为成功。
- intervalSeconds: 字段指定了重复间隔。
- timeoutSeconds: 字段指定了每次执行的超时时间。
- Continuous: 在检查过程中,如果一直是成功的,就会一直检查。如果是达到 failureThreshold 或者 deadline 就会结束检查。
- Synchronous: 在检查过程中,不管是达到了 failureThreshold,或者是达到 successThreshold,或者是 deadline 都会结束检查。
05、 架构
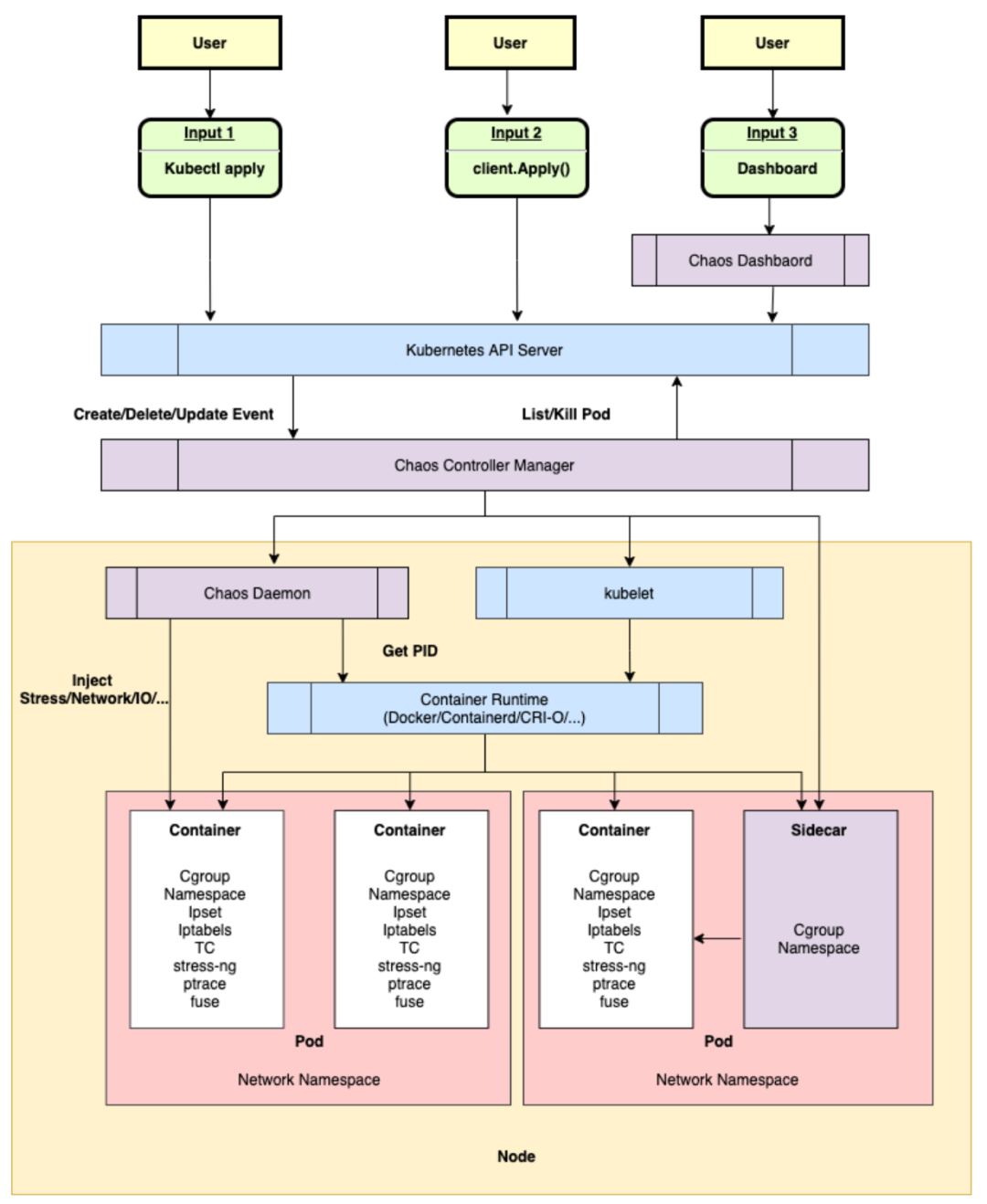
Chaos Mesh 主要包含以下三个组件:
-
ChaosDashboard: Chaos Mesh 的可视化组件,提供了一套用户友好的 Web 界面,用户可通过该界面对混沌实验进行操作和观测。同时,Chaos Dashboard 还提供了 RBAC 权限管理机制。
-
** Chaos Controller Manager: ** Chaos Mesh 的核心逻辑组件,主要负责混沌实验的调度与管理。该组件包含多个 CRD Controller,例如 Workflow Controller、Scheduler Controller 以及各类故障类型的 Controllers。
-
ChaosDaemon: Chaos Mesh 的主要执行组件。Chaos Daemon 以 DaemonSet的方式运行,默认拥有 Privileged 权限(可以关闭)。该组件主要通过侵入目标 Pod Namespace 的方式干扰具体的网络设备、文件系统、内核等。
06、 原理
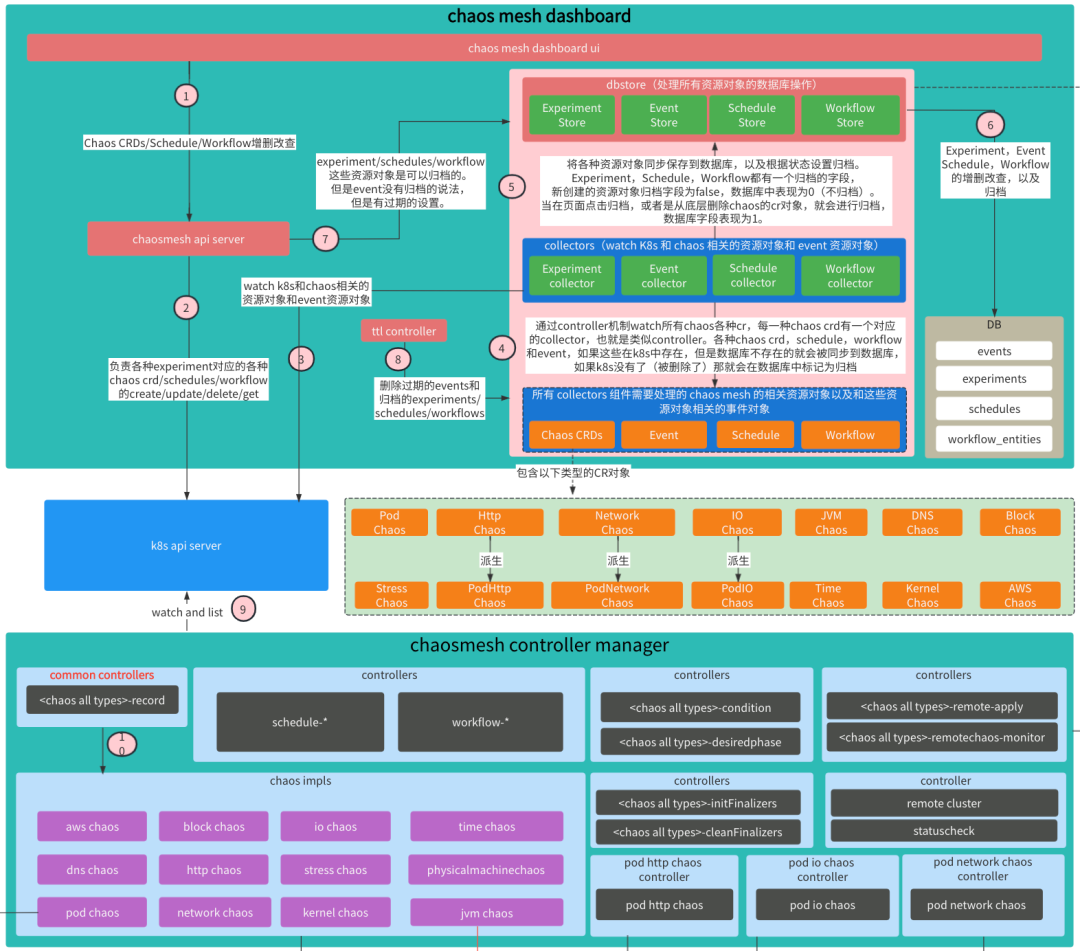
总结: 在 chaos dashboard 中,主要会包含以下一些核心的模块:用于展示的ui;用于接收前端请求的 chaosmesh api server;用于操作数据的dbstore;用于回收数据库中数据的 ttl controller;用于同步保存在 Kubernetes 中的 Chaos Mesh 相关的对象对象到数据库中的 collectors;还有数据库中的 4 张表:events、experiments、schedules、workflow_entities。以下进行相关工作流程的分析。
1. 用户在页面上创建,查询,归档 experiment(各种 chaos 对象)、schedule、workflow 等资源对象。或者是查询chaos的events。
2. 在 experiment(各种 chaos 对象)、schedule、workflow 等资源对象的创建请求到达 chaosmesh apiserver 之后,会由 chaosmesh apiserver 请求 Kubernetes 的 api server 完成 chaos 相关资源对象的创建请求。
3. 开始 watch Kubernetes 中的 chaos 相关的 cr 对象,从 Kubernetes 中获取 chaos 相关的对象之后,同步到数据库中。
4. chaos dashboard 的 collectors 开始 watch Kubernetes 中的 chaos 相关的 cr 对象。通过 controller 机制 watch 所有 chaos 各种 cr,每一种 chaos crd 有一个对应的 collector,也就是类似 controller。各种 chaos crd、schedule、workflow 的资源对象,如果这些资源对象在 Kubernetes 中存在,但是数据库不存在的就会被同步到数据库,如果 Kubernetes 没有了(被删除了)那就会在数据库中标记为归档。
5. 将各种资源对象同步保存到数据库,以及根据状态设置归档。Experiment、Schedule、Workflow 都有一个归档的字段,新创建的资源对象归档字段为 false,数据库的字段的值中表现为 0(不归档)。当在页面点击归档,或者是从底层删除 chaos 的 cr 对象,就会进行归档,数据库字段表现为 1。
6. 使用 dbstore 模块完成数据库的相关操作。dbstrore 可以理解成 orm 的实现部分,完成和数据库的通信和操作。
7. 在 dashboard 想查看一些总览信息,已经归档的实验,以及事件相关等操作,直接就走的数据库的逻辑部分,因为这部分数据在数据库中保存了。如果查询比较详细的信息,就会走 Kubernetes 的 api 部分,查询出具体 chaos 资源对象在 Kubernetes 的数据。
8. 还有一个比较独立的模块就是 ttl controller,主要用于处理在数据库中已经过期的数据,哪些数据的过期时间,都是部署的时候可以设置的,如对于 events 数据,这些数据不需要长期的持久化,那就可以在一段时间之后直接从数据库删除。还有对于已经被设置成归档的 chaos 的资源对象的数据,包括 Experiment、Schedule、Workflow,这部分数据包括在页面点击归档的,或者是直接走底层删除的,对于 Chaos Mesh 来说都是属于被归档的数据。归档的数据在一段时间之后也会失去业务价值,可以进行删除,所以这部分的数据也可以设置过期时间,通过 ttl controller 进行定期的回收。
数据库表结构:
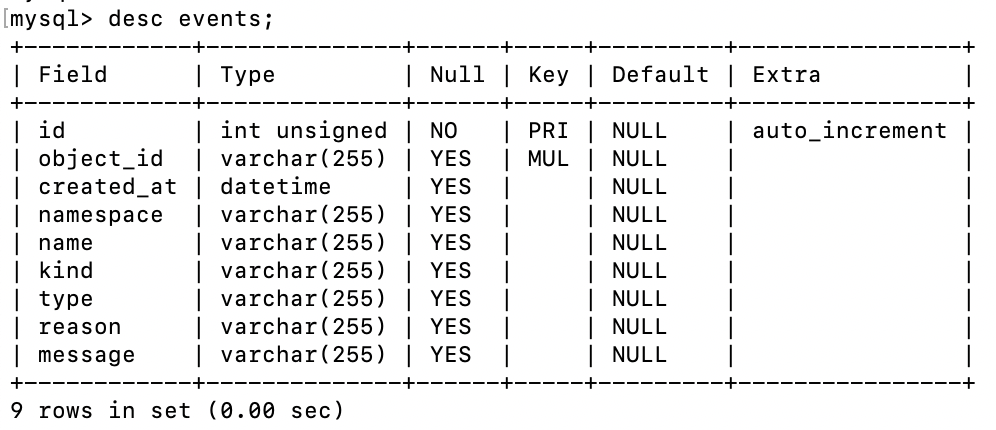
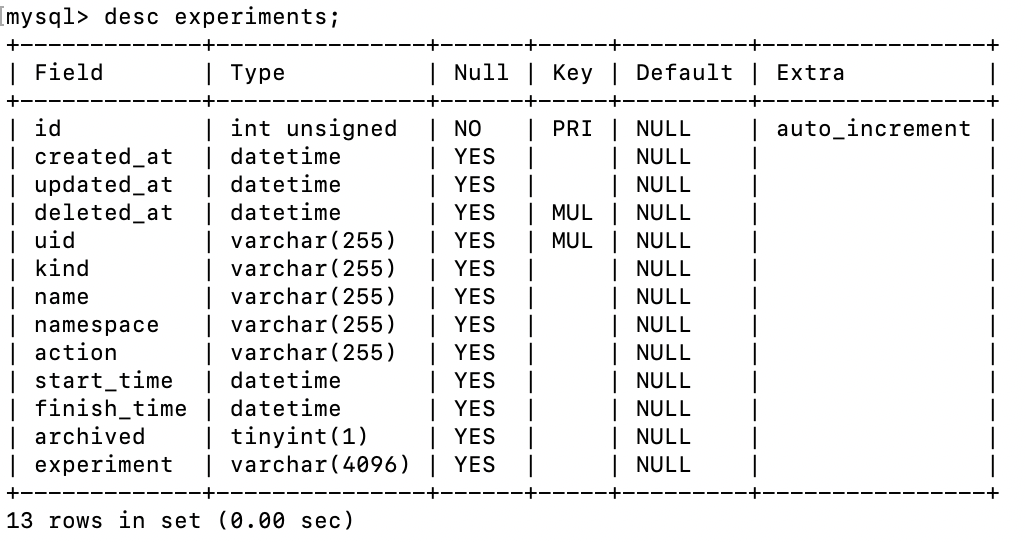
experiments表 用于保存从 Kubernetes 中同步回来的所有的 chaos 资源对象,如 PodChaos、NetworkChaos、IOChaos、KernelChaos、JVMChaos 等等,如果数据是被设置成归档,这部分归档的数据也会有有效期,过了有效期也会进行回收。如果从 Kubernetes 中删除资源对象,或者在页面上点击归档,在数据库中就会被标记成归档。
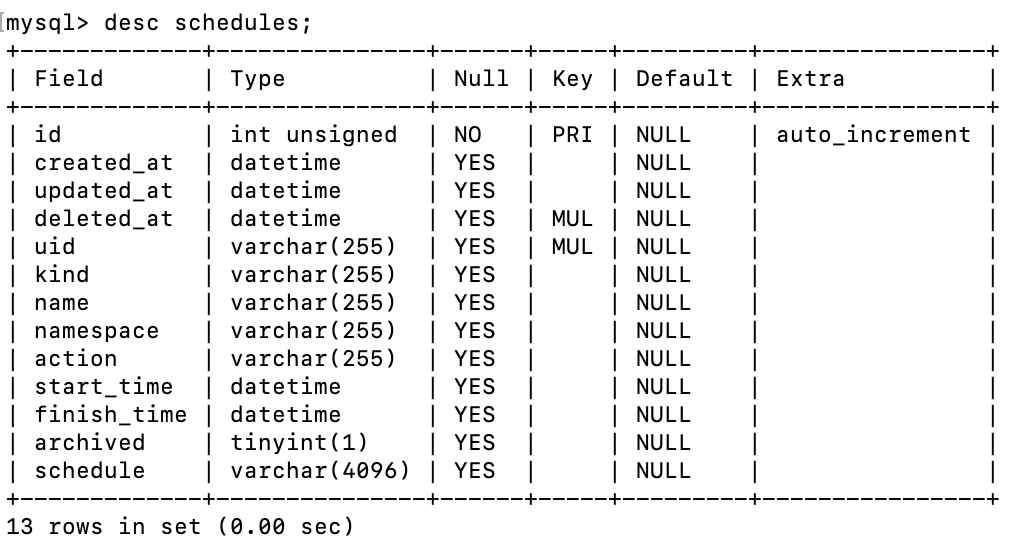
schedules表 用于保存从 Kubernetes 同步回来的 Schedule 资源对象,如果数据是被设置成归档,这部分归档的数据也会有有效期,过了有效期也会进行回收。如果从 Kubernetes 中删除资源对象,或者在页面上点击归档,在数据库中就会被标记成归档。

workflow_entities表 用于保存从 Kubernetes 同步回来的 Workflow 资源对象,如果数据是被设置成归档,这部分归档的数据也会有有效期,过了有效期也会进行回收。如果从 Kubernetes 中删除资源对象,或者在页面上点击归档,在数据库中就会被标记成归档。
** Chaos Controller Manager: **
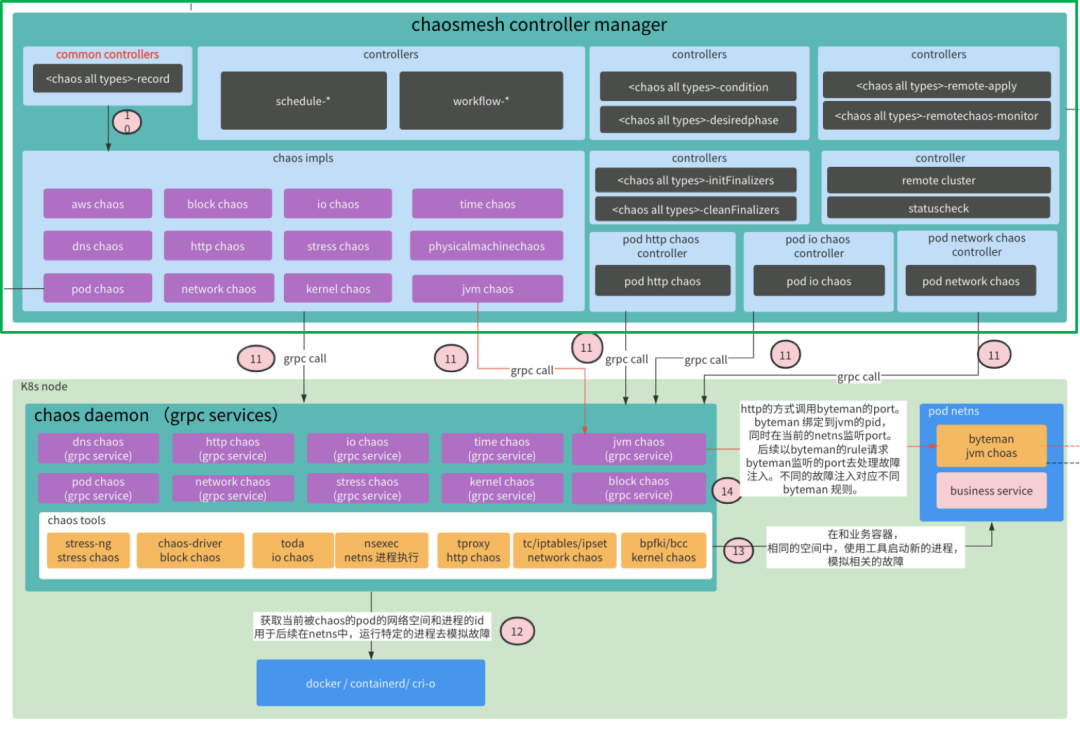
总结: chaos controller manager 中包含了很多 controllers。举例来说,在单集群环境下,对于 PodChaos 类型来说,它就有 PodChaos-record、PodChaos-initFinalizers、PodChaos-desiredphase、PodChaos-condition、PodChaos-cleanFinalizers 这 5 个 controllers。如果加上多集群的环境下,还有再有 PodChaos-remote-apply、PodChaos-remotechaos-monitor 这两个 controllers。那主要哪些 controllers,主要包含:
-
-record: 处理各种 chaos 资源对象的核心逻辑的controllers,调用 chaos impls 中具体的方法,去完成和 chaos daemon grpc service 的通信,最终由 chaos daemon 完成具体的故障注入和取消故障注入。 -
-condition: 处理各种 chaos 资源对象的 condition 的 controllers 。 -
**
-initFinalizer 和 -cleanFinalizer: ** 处理各种chaos 资源对象的 finalizer 的 controllers 。 -
**
-desiredphase: ** 处理各种 chaos 资源对象的 desire phase 的 controllers,根据不同的 phase 的状态进行处理,最终达到预定的效果 。 -
PodHttpChoascontroller: 处理 PodHttpChoas 资源对象逻辑的controller,由于 PodHttpChoas 是由 HttpChoas 派生出来的,所以可以理解成是用来处理 HttpChoas 的 controller。完成给 Pod 注入 http 类型的故障,如中断 session,请求和响应的报文等等。
-
PodIOChaoscontroller: 处理 PodIOChaos 资源对象逻辑的 controller,由于 PodIOChaos 是由 IOChaos 派生出来的,所以可以理解成是用来处理 IOChaos 的 controller。完成给 Pod 注入 io 相关的故障,如为文件系统调用加入延迟,使文件系统调用返回错误等等。
-
PodNetworkChaoscontroller: 处理 PodNetworkChaos 资源对象逻辑的 controller,由于 PodNetworkChaos 是由 NetworkChaos 派生出来的,所以可以理解成是用来处理 NetworkChaos 的 controller。完成给 Pod 注入网络相关的故障,如网络断开、网络分区、高延迟、高丢包率、包乱序等等。
-
**
-remote-apply: ** 多集群下,处理各种 chaos 资源对象的 remote-apply 的 controllers ,这里的 remote-apply 就是指的是在远程集群 apply chaos 资源对象,以此来完成在远处集群中也能注入需要的故障。要想在远程集群中 apply chaos 资源对象,首先需要在管控集群中创建 chaos 资源对象,然后由管控集群去同步到远程集群,来完成在远处集群中创建chaos 资源对象,完成故障的注入。 -
**
-remotechaos-monitor: ** 多集群下,处理各种 chaos 资源对象的 remotechaos-monitor 的 controllers,用于同步管理集群和远程集群的 chaos 资源对象。当管理集群 chaos 资源对象被删除了,那远程集群上的也要被删除,以此保持一致性。 -
remoteclustercontroller: 处理 RemoteCluster 资源对象,是多集群能力相关的 controller,主要用于完成多集群下,远程集群的 join 能力,作为 remote-apply 和 remotechaos-monitor 能力的前提条件,因为要想在远程的集群注入故障,那前提是远程的集群提前需要安装 Chaos Mesh 的组件,这个 remotecluster controller 就是来做这个事情的。
-
schedule-*: 处理 Schedule 相关的 controllers。包括 schedule-active controller,schedule-cron controller,schedule-gc controller,schedule-pause controller。
-
workflow-*-reconciler: 处理 Workflow 相关的 controllers。包括workflow-entry-reconciler,workflow-serial-node-reconciler,workflow-parallel-node-reconciler,workflow-deadline-reconciler,workflow-chaos-node-reconciler,workflow-task-reconciler,workflow-statuscheck-reconciler,workflow-abort-node-reconciler,workflow-abort-workflow-reconciler。
-
statuscheckcontroller: 用于处理 StatusCheck 资源对象,执行状态检查的任务,目前支持 http 类型的检查方式。
ChaosDaemon:
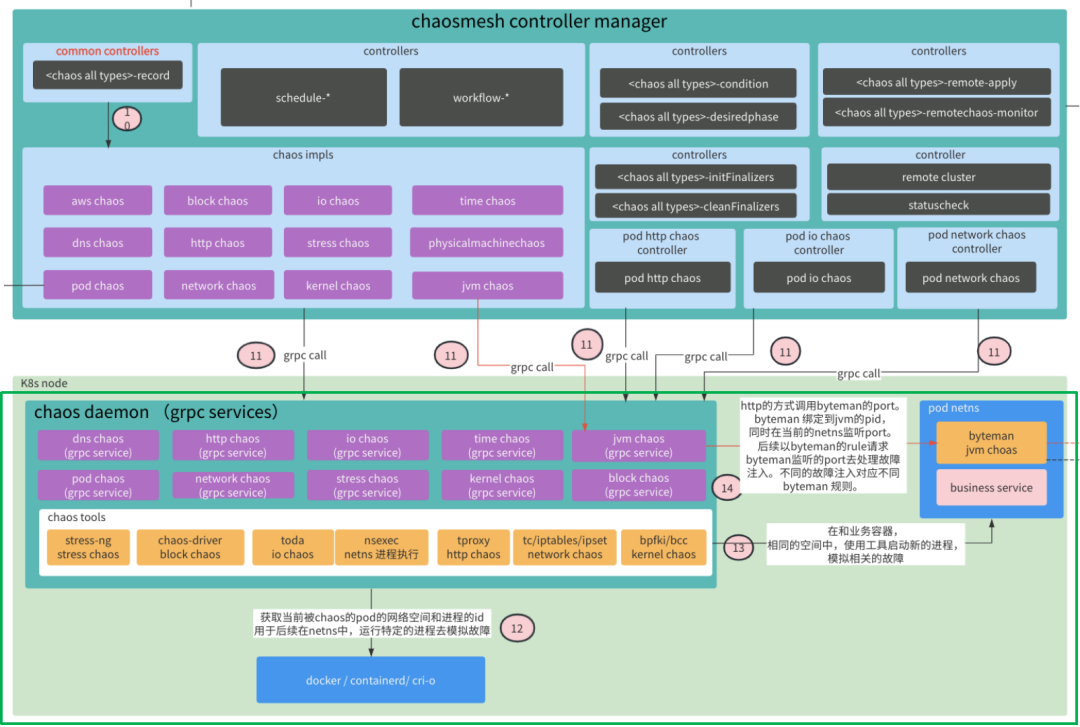
总结: chaos daemon 是承担了真正执行故障注入的能力。其中内部提供了很多种 chaos 的能力,以 grpc service 的方式提供给 controller 层。主要包含如 DNS Chaos、HttpChaos、IOChaos、TimeChaos、JVMChaos、PodChaos、NetworkChaos、StressChaos、KernelChaos、BlockChoas 等这些场景的故障注入能力。主要的逻辑通过获取当前被 chaos 的 Pod 的网络空间和进程的 id,用于后续在 netns 中运行特定的进程去模拟故障。在实现的时候,使用了很多的外部的工具或是自己实现的独立组件(包括 bpfki,tproxy 和 chaos-driver 等),如:
-
stress-ng: 可以用于模拟 cpu 和内存压力。
-
toda: 可以用于模拟 pod 的 io 故障。
-
bpfki: 一个基于 BPF 来模拟内核故障的组件。通过使用 BPF 在指定内核路径上注入基于 I/O 或内存的故障。
-
bcc: 可以用来模拟内核故障,bcc 是一个基于 eBPF 能力的工具,要根据需求编写相关 bcc 风格的脚本。
-
byteman: 通过字节码注入技术,模拟 jvm 相关的很多故障类似(之前的版本是使用的 jvm-sandbox)。byteman 绑定到 jvm 的 pid,同时在当前的netns 监听 port。后续以 byteman 的 rule 作为请求,去访问 byteman 监听的port去注入故障。不同的故障注入对应不同 byteman 规则。
-
nsexec: 可以用于在 pod 的网络命名空间执行命令。
-
tc / iptables / ipset: 可以用于模拟 pod 的网络控制。
-
tproxy: 使用透明代理的技术,用来模拟 pod 的 http 的故障注入,如替换请求和响应的报文,中断 session 等。
-
chaos-driver: 它是一个内核的模块,在使用前需要安装相关模块。主要用于注入 block 的故障,如增加 block 的延迟等。
07、 总结
随着云原生的不断普及,以及随着应用上云的步伐不断前行,对云原生下的各种应用的稳定性要求会越来越高,混沌工程的场景和需求也会越来越多,要求也会越来越高。同时看到 CNCF 社区已经有三个类似的项目,同时还有非 CNCF 的项目,总体看来,混沌工程的社区发展也是不错的。
相关链接:
https://chaos-mesh.org/zh/docs/
https://github.com/chaos-mesh/chaos-mesh
评论区