


文章结构

导语
微信、微博、抖音、快手、今日头条、知乎、Facebook、Instagram…,为什么在这些APP上我们总是不知不觉地花了好多时间,“刷”得不亦乐乎,根本停不下来?在产品结构上,这些社交&内容类app中,都包含Feed流。Feed流是一种呈现内容给用户并持续更新的方式,我们只需要进行“刷新”这一的动作,即可获得大量智能算法推荐给我们的信息,简单高效,使得我们不断刷新而沉溺于其中。Feed流该如何设计,我们一起来一探究竟。

什么是Feed流
Feed,源自早期的RSS(Really SimpleSyndication,简易信息聚合)。最早的应用是RSS阅读器,是一个可以收集你关心的网站更新内容的一个应用。比如说,你可以在RSS阅读器中加入你关心的网站的网址,当它们有更新的时候,你就可以在RSS阅读器中直观的看到,而不用分别打开两个网页了。
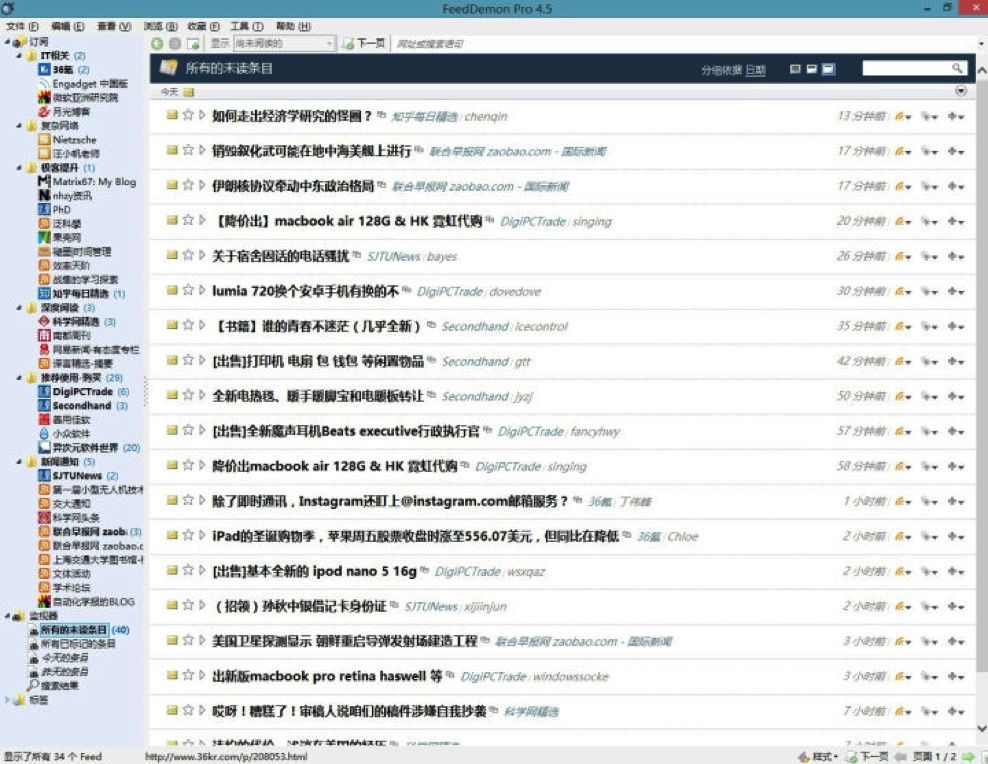
从Wikipedia对“Web feed”的定义中可以看出,Feed是将用户主动订阅的若干信息源组合在一起形成 内容聚合器,帮助用户持续地获取最新的订阅源内容。Feed流是持续更新并呈现给用户 内容的信息流 。
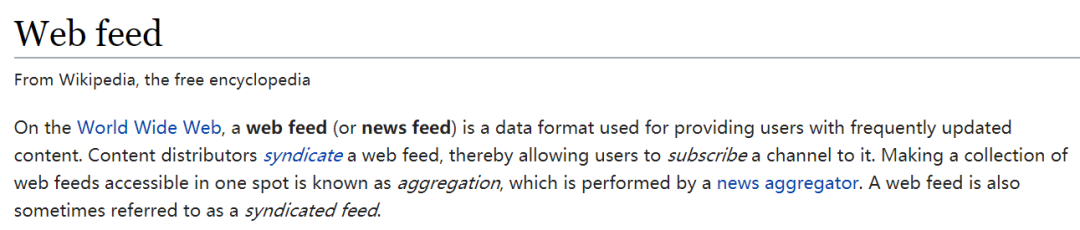
2006年,Facebook推出了“News Feed”, 将好友或者关注对象作为信息源 。当好友足够多或者好友发布动态足够频繁时,用户能源源不断的收到内容。
- 注,关于News Feed的演变,戳->《The Evolution of Facebook News Feed》
https://mashable.com/2013/03/12/facebook-news-feed-evolution/#rTpnFtN97Pq3
Feed系统架构
从《深入分布式缓存》一书"缓存在社交网络Feed系统中的架构实践"一章中,对Feed系统的构建,以及Feed的聚合、刷新、缓存都进行了详细介绍。
1. Feed刷新机制
对于中小型的Feed系统,feed数据可以通过同步 push模式进行分发。用户每发表一条feed,后端系统根据用户的粉丝列表进行全量推送,粉丝用户通过自己的inbox来查看所有最新的feed。
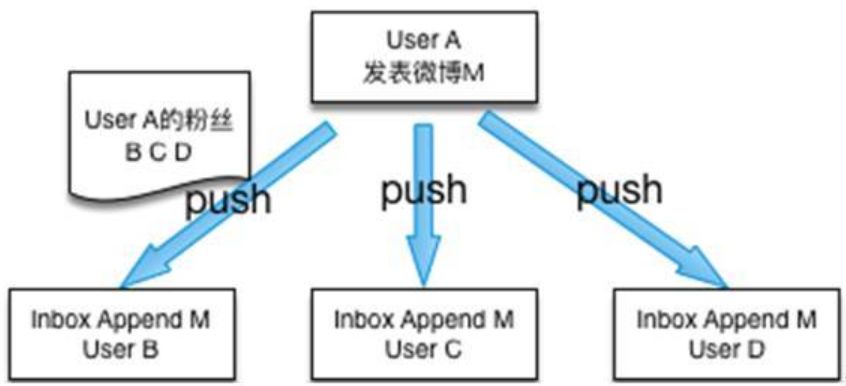
随着业务规模的增长,用户的平均粉丝不断增加,特别是大V用户的粉丝的大幅增长,信息延迟就会时有发生,单纯的push无法满足性能要求。同时考虑社交网络中多种接入源,移动端、PC端、第三方都需要接入业务系统。于是就需要对原有架构进行模块化、平台化改进:1)把底层存储构建为基础服务,然后基于基础服务构建业务服务平台。
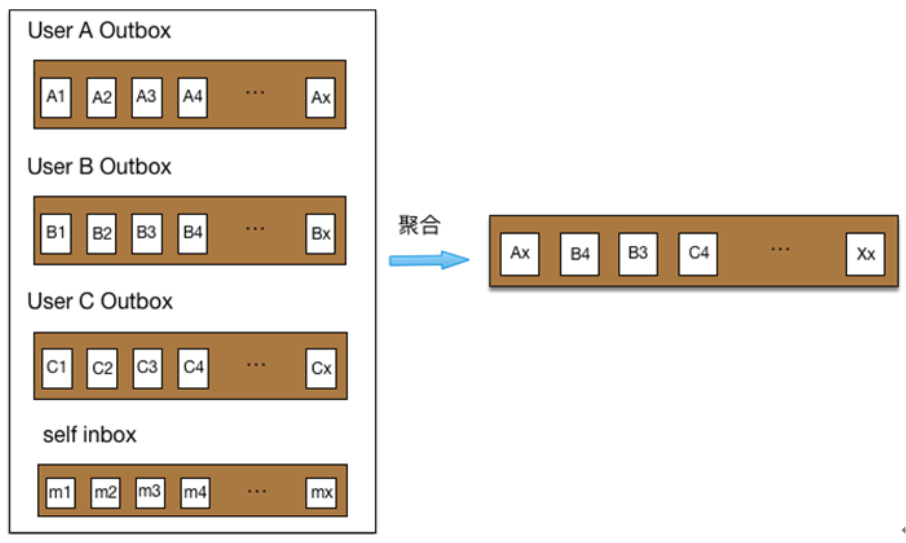
2)对数据存储进行了多维度拆分,并大量使用cache进行性能加速,同时将同步push模式改成了异步hybrid模式,即 pull+push模式 :
-
用户发表feed后,首先写入消息队列,由队列处理机进行异步更新,更新时不再push到所有粉丝的inbox,而是存放到发表者自己的outbox;
-
用户查看时,通过pull模式对关注人的outbox进行实时聚合获取。基于性能方面的考虑,部分个性化数据仍然先push到目标用户的inbox。
-
用户访问时,系统将用户自己的inbox和TA所有的关注人outbox一起进行聚合,最终得到Feed列表。
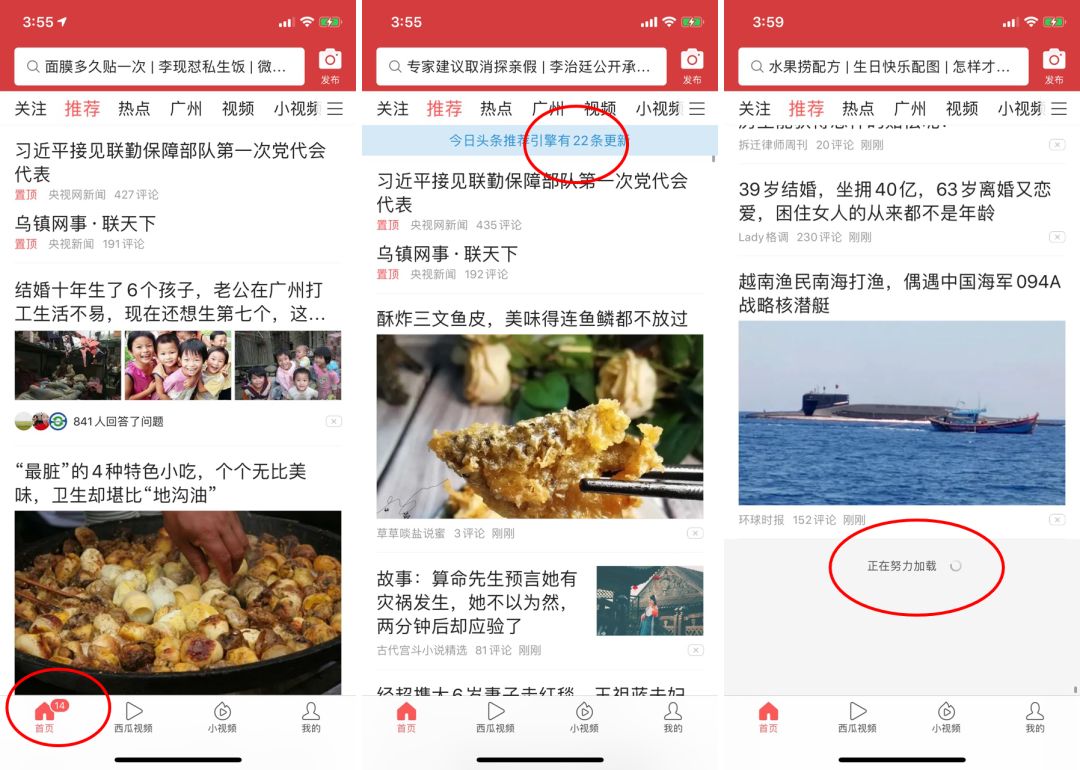
比如,停留在今日头条的推荐Feed流一段时间后,会以红点的形式提示有N条新内容可以主动拉取;当下拉刷新/上滑加载时,一次只取出22条(符合一次浏览的统计中位数)内容。
2. Feed系统构建
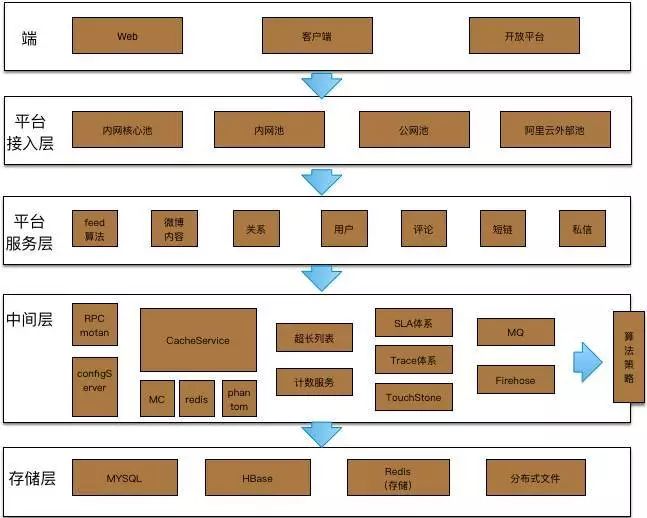
对于大型Feed系统,需要对Feed架构进行服务化、云化改进,最终形成一个Feed系统架构:
① 对外: 主要以 移动客户端、web主站、开放平台 三种方式提供服务,并通过平台接入层访问Feed平台体系。
② 平台服务层: 把各种 业务进行模块化拆分。把诸如Feed计算、Feed内容、关系、用户、评论等分解为独立的服务模块,对每个模块实现服务化架构,通过标准化协议进行统一访问。
③ 中间层: 通过各种服务组件来构建 统一的标准化服务 体系。如motan提供统一的rpc远程访问,configService提供统一的服务发布、订阅,cacheService提供通用的缓存访问,SLA体系、Trace体系、TouchStore体系提供系统通用的健康监测、跟踪、测试及分析等。
④ 存储层: 主要通过Mysql、HBase、Redis、分布式文件等 对业务数据提供落地存储服务 。
为了满足海量用户的实时请求,大型Feed系统一般都有着较为严格的SLA,如微博业务中核心接口可用性要达到99.99%,响应时间 在10-40ms以内;对应到后端资源,核心单个业务的数据访问高达百万级QPS,数据的平均获取时间要在 5ms 以内。因此在整个Feed系统中,需要对 缓存体系进行良好的架构并不断改进。
-
SLA:Service-Level Agreement,服务等级协议,是在一定开销下为保障服务的性能和可靠性,服务提供商与用户间定义的一种双方认可的协定。通常这个开销是驱动提供服务质量的主要因素。
-
QPS: Queries-per-second,每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
3. Feed聚合过程
Feed系统的核心数据主要包括:用户/关系、feed id/content以及包含计数在内的各种feed状态。Feed系统处理用户的各种操作的过程,实际是一个 以核心数据为基础的实时获取并计算更新 的过程。
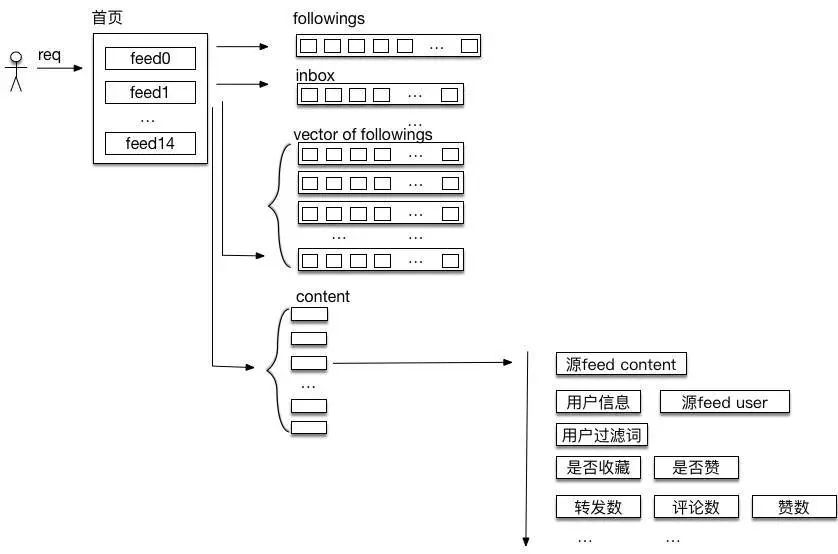
以刷新微博首页为例,处理用户的一个操作请求,主要包括 关注关系的获取 、 feed id的聚合 、 feed内容的聚合三部分,最终转换到资源后端就是一个获取各种关系、feed、状态等资源数据并进行聚合组装的过程。这个过程中,一个前端请求会触发一次对核心接口friends_timeline的请求,到资源后端可能会存在1~2+个数量级的请求数据放大,即Feed系统收到一个此类请求后,可能需要到资源层获取几十数百甚至上千个的资源数据,并聚合组装出最新若干条(如15条)微博给用户。整个Feed流构建过程中,Feed系统主要进行了如下操作:
① 根据用户uid获取关注列表;
② 获取用户自己收到的微博 ID 列表(即 inbox);
③ 对这些 ID 列表进行合并、排序及分页处理后,拿到需要展现的微博 ID 列表;
④ 根据这些 ID 获取对应的微博内容;
⑤ 对于转发feed进一步获取源feed的内容;
⑥ 获取用户设置的过滤条件进行过滤。
⑦ 获取feed/源feed作者的 user 信息并进行组装;
⑧ 获取请求者对这些feed是否收藏、是否赞等进行组装;
⑨ 获取这些feed的转发、评论、赞等计数等进行组装;
⑩ 组装完毕,转换成标准格式返回给请求方。
4. Feed缓存设计 ****
Feed请求需要获取并组装如此多的后端资源数据,同时考虑用户体验,接口请求耗时要在 100ms(微博业务要求小于40ms)以下,因此Feed系统需要大量使用缓存(cache),并对缓存体系进行良好的架构。缓存体系在Feed系统占有重要位置,可以说缓存设计决定了一个Feed系统的优劣。
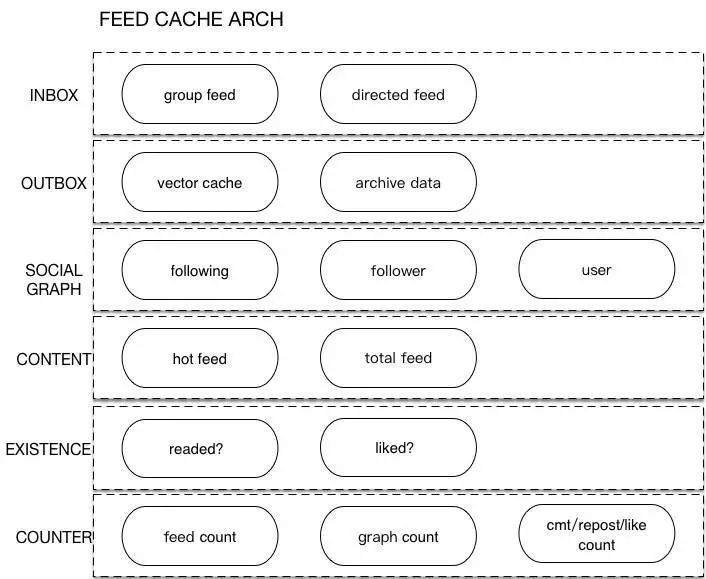
一个典型的Feed系统的缓存设计,主要分为INBOX、OUTBOX、SOCIAL GRAPH、CONTENT、EXISTENCE、CONTENT共六部分。
① INBOX缓存层: 用于存放 聚合效率低的feed id (类似定向微博directedfeed)。当用户发表只展现给特定粉丝、特定成员组织的feed时,Feed系统会首先拿到待推送(push)的用户列表,然后将这个feedid推送(push)给对应粉丝的INBOX。因此INBOX是以访问者UID来构建key的,其更新方式是先gets并本地,变更后再cas到异地Memcached缓存。
② OUTBOX 缓存层: 用于直接缓存 用户发表的普通类型feed id,这个cache以发表者UID来构建key。其中outbox又主要分为vectorcache和archive datacache;vectorcache用于缓存最新发表的feedid、commentid等,按具体业务类型分池放置。如果用户最近没有发表新feed,vector cache为空,就要获取archivedata里的feed id。
③ SOCIAL GRAPH缓存层: 主要包括 用户的关注关系及用户的user信息。用户的关注关系主要包括用户的关注(following)列表、粉丝(follower)列表、双向列表等。
④ CONTENT 缓存层: 主要包括 热门feed的content、全量feed的content。热门feed是指热点事件爆发时,引发热点事件的源feed。由于热门feed被访问的频率远大于普通feed,比如微博中单条热门feed的QPS可能达到数十万的级别,所以热门feed需要独立缓存,并缓存多份,以提高缓存的访问性能。
⑤ EXISTENCE 缓存层: 主要用于缓存 各种存在性判断的业务 ,诸如是否已赞(liked)、是否已阅读(readed)这类需求。
⑥ COUNTER缓存层: 用于缓存 各种计数。Feed系统中计数众多,如用户的feed发表数、关注数、粉丝数,单条feed的评论数、转发数、赞数及阅读数,话题相关计数等。
Feed流展现形式
一个Feed流需要解决两个核心问题:展示给用户什么内容、这些内容该怎么排序。常见的排序方式有时间排序、重力排序、智能排序。
1. 时间排序
① 特点: 不对用户主动要求获取的内容进行筛选,展 示 用户好友发的内容 ,同时所有的内容 按照时间排序 。
② 适用: 需要内容 提供方非常克制 ,同时也需要用户对这些内容 足够关注 。
③ 优点: 随时更新,吸引用户随时打开使用;每次更新的部分都有限也保证了大部分用户不会错过任何消息。
④ 缺点: 内容呈现效率最为低下。
⑤ 案例: 微信朋友圈的内容是用户自己的个人展示,注定不会大量更新;同时选择都是基于熟人关系,能引起用户足够的关注。
2. 重力排序
① 特点: 兼顾热度和更新时间, 用户表现出喜好的内容 都推给用户, 按照时间衰减因素和内容受欢迎程度综合排序 。
② 适用: 每天有 大量更新 ,同时大部分内容 没有太大用户价值 。需要考虑该如何选择 参数 保证最后的展示效果。
③ 算法: 重力排序算法中,对于一个在Feed流中的内容而言,有两种力量:重力和拉力。
-
重力:是持续让内容往下掉的力,这个重力就是时间,因为新的内容会把老的内容刷下去
-
拉力:是让内容排序往前的力,比如知乎的赞、贴吧的回复
*** Reddit的核心排序算法**
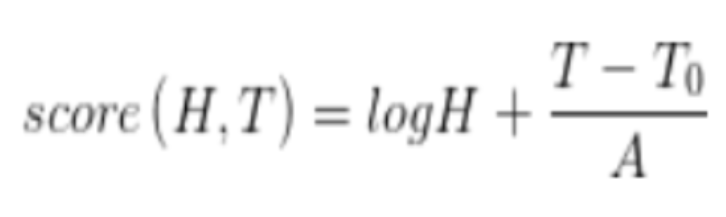
其中,
H:代表内容热度的值,比如说收到的赞、浏览量,也可以是综合类似的指标加权求和得到的值。
T:代表内容发布的时间,T-T0用来衡量一个内容的新旧程度,单位为秒,T-T0越大,则代表内容越新。
A:自定义常量,A越大,T-T0的影响力越小,则内容更新的越慢。一般而言初始值可以用36000,10个小时的秒数,后续不断迭代。
④ 案例: 豆瓣中“我的小组”里小组的排序,有最新回复且评论数多的小组,会被放在feed流的顶端展示。
3. 智能排序
① 特点: 将用户关心的内容进行了更加细化的测量,从而将用户本人 更感兴趣的内容 推送出来。
② 适用: 需要考虑是否有足够的技术实力和产品自制力(过度的商业化容易成为用户体验的头号凶手。)
③ 算法: 以Facebook早期的EdgeRank算法为例,影响feed流排序,主要有三个因素:
-
亲密度(Affinity Score):考虑该信息的来源者和用户之间交流是否频繁密切。 例如家人发的一条状态肯定比某个不太熟的同学发的要重要。
-
生产成本(Edge Weight):成本越高权重越大。 例如好友发布了9张图片的成本比起发了9个字成本高,前者就会被优先推荐;又例如发布的成本远高于点赞,所以原创内容的优先级高于因为好友点赞而被用户获知的消息。
-
新鲜程度(Time Decay):越近发生的事越容易被推荐,一般都是用一个指数衰减函数来量化动态的新旧程度。
EdgeRank 排序算法
E = uwd
其中,
E:每个事件对这个用户而言的权重。
u:事件生产者和观察者之间的亲密度。
w:边权重。
d:时间衰减因子。
④ 案例: 微博中“我的关注”的微博,不是简单按时间/热度进行排序,当用户刷新timeline时,会按照一定的规则,一次只取出15-30条内容,而不是全部未读内容。算法优先取权重高的且刚发布的内容,取完以后用户再刷新,再从 未读池 里边接着提取。就是“智能分批提取数据”,而不是传统的“一次性提取全部未读数据”。
Feed流页面设计
下面主要以Instagram为例进行分析。
1. 相关背景
2010年,智能手机兴起,用手机拍照质量差。 这一年,Instagram创立,它是一款图片、视频分享社交App。支持用户随时随地、简单快捷地完成拍摄、编辑,满足用户借助智能手机而非昂贵的摄影器材就能拍出美观的照片视频,并与他人分享的基本需求。
2010~2013年,产品初期,Instagram的核心用户一批是业余/专业摄影师、艺术家,他们注重画质。随着产品功能的逐渐完善,产品定位不断打磨,现阶段目标用户是热爱分享图片/视频以及通过图片/视频获取信息的相对年轻的用户群体。 可以分为两大类:
-
创作者: 如摄影师、艺术家、明星、其他兴趣类博主。 特点是: 粉丝数量大 、内容发布频次高、内容质量好。
-
普通用户:使用Instagram的主要目的是分享、社交和获取信息。
目前,美国是Instagram的全球最大市场,但80%的用户来自美国以外的国家/地区,而美国地区用户月活最高(1.2亿),巴西、印度用户月活分别居于第二、第三位(Instagram官方数据)。
2. Feed流分析
用户可以在Feed流浏览自己关注的用户发布的帖子、 关注用户发布的快拍、 关注的话题所囊括的帖子、 品牌广告、系统推荐的其他内容等,用户可以给帖子点赞、评论、分享、收藏,以及举报、不看、停止关注等。
① 用户痛点: 综合类社交平台各类信息冗杂,缺乏有趣的、感兴趣的图片/视频内容,消遣空闲时间的方式单一。
② 用户需求: 想要方便快捷查看好友或感兴趣的人的动态。
③ 解决方案: 关注Feed流专注于展示基于用户兴趣和关系的内容。
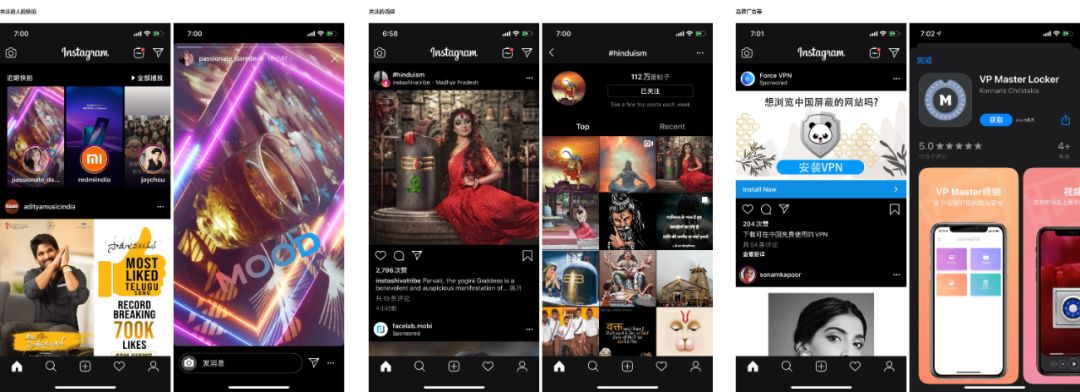
④ 页面设计 :
-
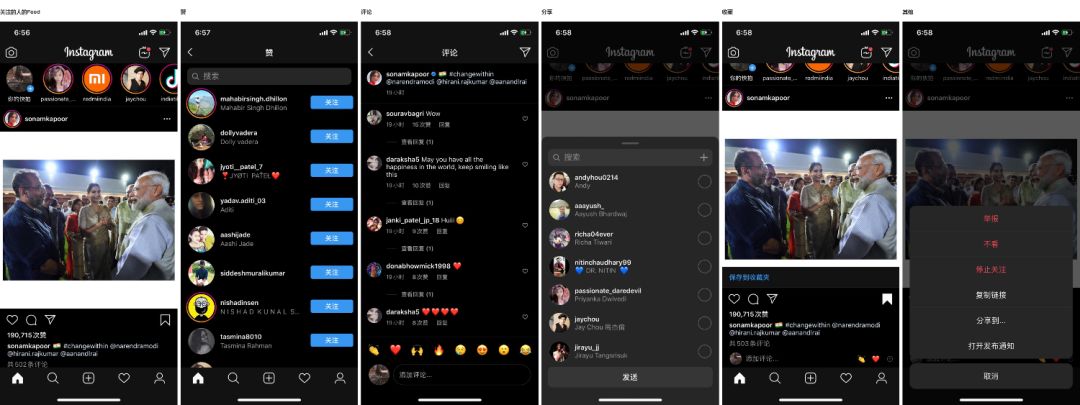
浏览:
-
内容排序上: 优先根据用户行为(如与好友的关系、关注的话题标签、点赞互动等)产生的数据来对所有新帖进行排序,时间顺序不是排序的优先级标准。
-
内容展示上: 如果过去的新帖子都看完了,则会提示用户“You’re All Caught up”, 这样可以让用户清楚地了解自己到自己已经刷过了哪些帖子,而可以选择不去重复再刷一遍。
-
卡片布局上:支持图片的Landscape(横向)和Portrait(画像)的全尺寸排列格式以适应不同的照片类型的布局需 求,并且 占满整个屏幕的宽度而让屏幕两侧不留白边。
-
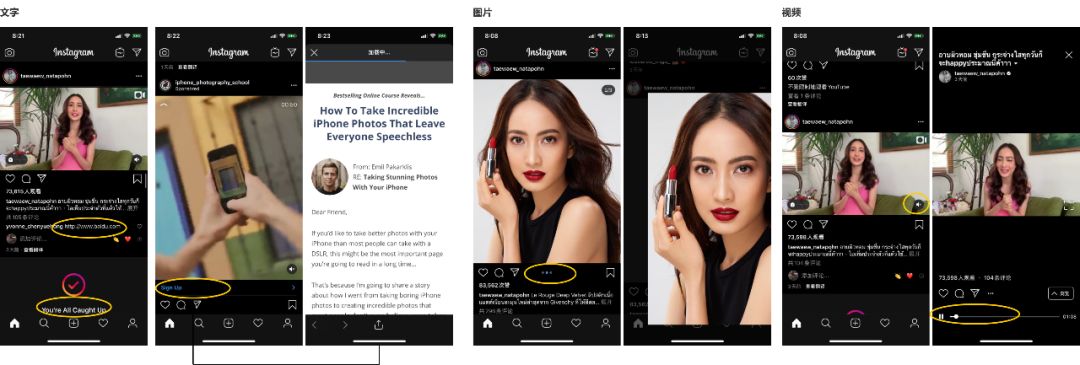
浏览体验上:【文字】 官方禁止用户在帖子文案和评论中添加一切外链(即外链只以纯文本形式呈现,而无法通过显示超链接来点击跳转),但是为了商业化的需要,Feed流中正规投放的广告可以添加品牌的第三方链接,方便用户浏览商品和完成购物。 【图片】可以在当前直接两只手指往外拖动照片放大,浏览细节。【视频】视频时长最大限制为60秒,当刷出的视频占屏幕的主要帖子部分时,即使没有完全显示于屏幕中,视频将开始自动播放;另外,视频无法通过进度条来调整播放进度,每次只能从头开始全部播放;可以选择静音、暂停;可以进入视频详情页调整播放进度。
-
-
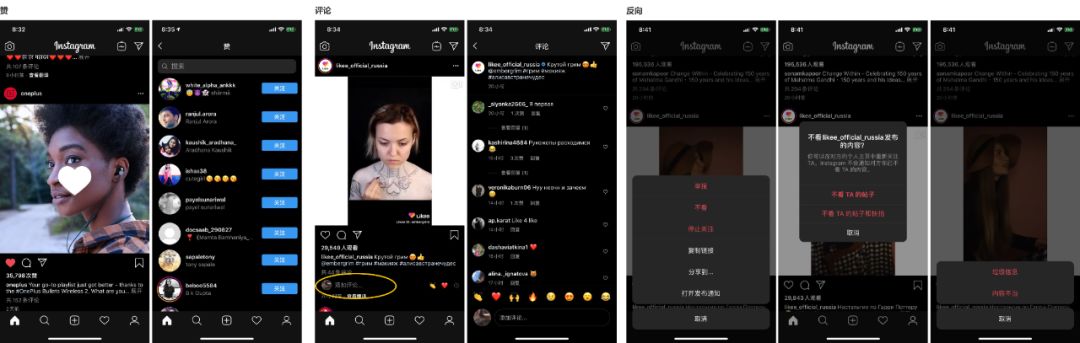
互动:
-
赞: 用户双击图片或点击帖子下方的爱心即可对帖子进行点赞,并且查看其他赞的用户、关注对方,也可以对帖子下方的任意评论进行点赞。
-
评论:当用户在当前卡片停留3s后,页面上自动展开评论输入框引导用户评论;在Feed流中只展示最新一条评论,可以进入评论详情也查看更多, 对帖子下方的任意评论进行赞、回复、翻译等。
-
反向操作:【不看】 在不停止关注好友的情况下,用户可以选择“不看TA的帖子或快拍”,让用户避免看到不想看的帖子,同时又能维护在平台上的社交关系,用户自由控制的选择权较大。【举报】对于违规的内容,可以及时进行举报,协助平台维持内容的质量。
-
如何评估Feed流的效果
Feed流是用户与内容的匹配,目的是从大量内容中找到用户最喜欢的内容。细化到具体的评估指标,可以从以下维度考虑:
① 前n个点击量 : 例如考虑前10个内容中,用户点击的占比来评估效果
② 点击量 : 这是最直观的数据。用户点击该Feed流的内容越多,说明用户喜爱度越高
③ 停留时长: 用户在Feed流的内容中停留时间越长,说明用户对该Feed流越感兴趣
④ 活跃度: 用户点赞、评论、收藏、转发等行为
参考资料:
《深入分布式缓存:从原理到实践》.机械工业出版社.于君泽 等2017
《基础知识讲解:什么是feed流?》.人人都是产品经理.Ronie.2018
《视奸渣浪的feed流算法》.人人都是产品经理.纯银V.2016
评论区