


近期接到一个点赞系统的需求,回想起以前也做过类似的需求,需求核心一致,但侧重点不同。借机梳理一下常见点赞系统的业务特点,并形成一个通用设计。文中的 点赞 只是一种业务场景,此设计可扩展到 已读、收藏 等需要记录计数和部分元数据的场景,不过多叙述。
业务场景
点赞常见的业务场景,大体上分为三类:
-
以数量展示为主的场景,用户对数量的变动非常敏感,对计数访问频繁,如知乎、B站、Quora等
-
对数量和点赞用户变更都比较敏感,有时间线需求,如微信朋友圈、微博等
-
对业务扩展性要求较高,但对系统并发度没什么要求
这三类业务场景有一些共同的业务特点:
-
对计数敏感,统计数量和是否点赞是高频访问场景
-
要求较高的可用性(响应速度)和一致性
-
对点赞用户敏感,如查询点赞历史,查询共同点赞用户等
-
对点赞时序敏感,如关注前百名点赞用户 · 可能会基于时间纬度进行数据查询,如查询一天内的点赞用户等
把这些业务场景转化为具体系统功能:
-
查询点赞数目
-
查询用户是否已点赞
-
点赞/取消点赞
-
查询点赞历史
这些系统功能转化为技术需求就是:
-
需要实现一个计数器
-
需要维护用户和点赞对象之间的关系
-
需要记录行为时间
接下来我们根据不同的业务场景和系统要求,进行技术方案设计。
方案1:基于优先队列
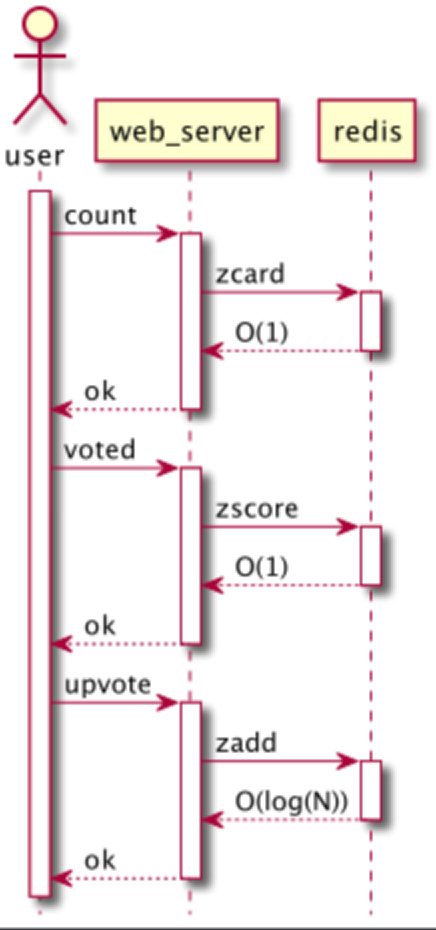
选型: Redis 基本设计
-
以点赞主体的唯一键建立ZSet
-
以点赞用户ID和类型作为ZSet元素
-
以点赞时间作为ZSet的Score
-
从用户维度查询点赞记录,以用户为主体建立ZSet
主要业务场景实现方案
-
点赞数 zcard O(1)
-
是否点赞 zscore O(1)
-
点赞/取消点赞 zadd/zrem O(log(N))
-
查询点赞历史 zrangebyscore O(log(N)+M)
业务时序图
设计优势
-
高可用(并发响应)、高一致性,可以较好支持ToC的场景
-
常见业务场景运算快速
-
易扩展。千万级别的数据量,Redis单机可以支撑,如果数据量增长,可以基于Cluster模式实现水平扩展。
设计缺陷
-
可能存在数据丢失,但在点赞这个业务场景下是可接受的
-
存在数据量过大的风险,需要对数据增长速度做好评估
方案2:基于关系型数据库
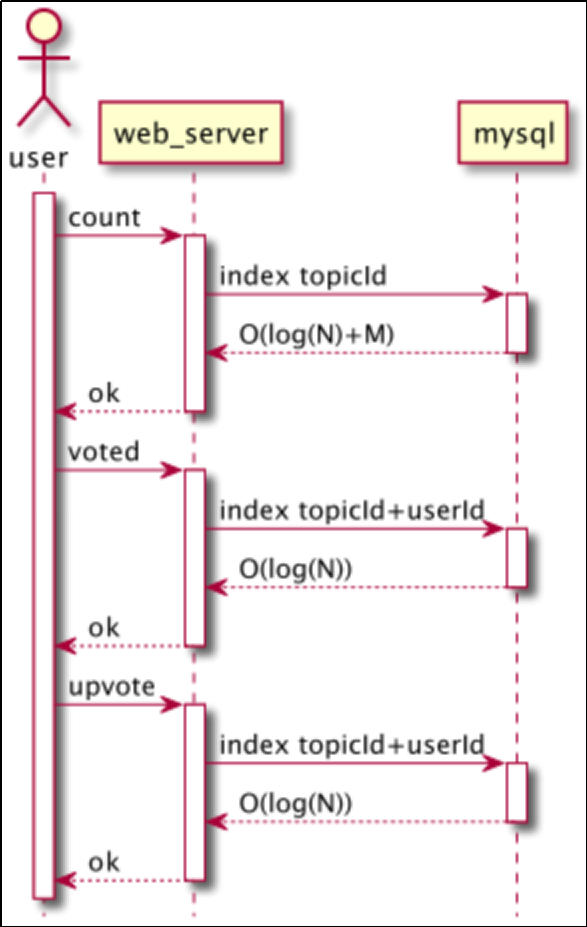
选型: Mysql 基本设计
-
保存点赞主体ID、用户ID、行为时间以及部分扩展性的元数据
-
以点赞主体的唯一键和用户ID建立唯一索引
-
如果需要以用户维度查询点赞记录,对用户ID建立索引
-
如果对行为时间敏感,可以对行为时间创建索引
主要业务场景实现方案
-
点赞数,利用点赞主体索引进行聚合查询 O(log(N)+M)
-
是否点赞,利用点赞主体和用户为索引进行查询 O(log(N))
-
点赞/取消点赞,利用点赞主体和用户为索引插入或删除数据 O(log(N))
-
查询点赞历史,利用点赞主体索引进行查询 O(log(N) *log(M))
业务时序图
设计优势
-
高一致性,不会因为数据库宕机造成数据丢失
-
更好的扩展性,磁盘空间充裕,可以支持更丰富的业务扩展设计
-
更低实现成本,不会因为数据量过快增长产生硬件焦虑
设计缺陷
-
可用性较低,应对并发度稍高的场景会存在性能问题
-
主要业务场景的实现复杂度比方案一更高,在 log(N) 到 M*log(N) 之间
-
水平扩展性较低,需要手动进行分库分表等设计以保证大数据量下的性能
方案3:基于缓存+消息队列+关系型数据库
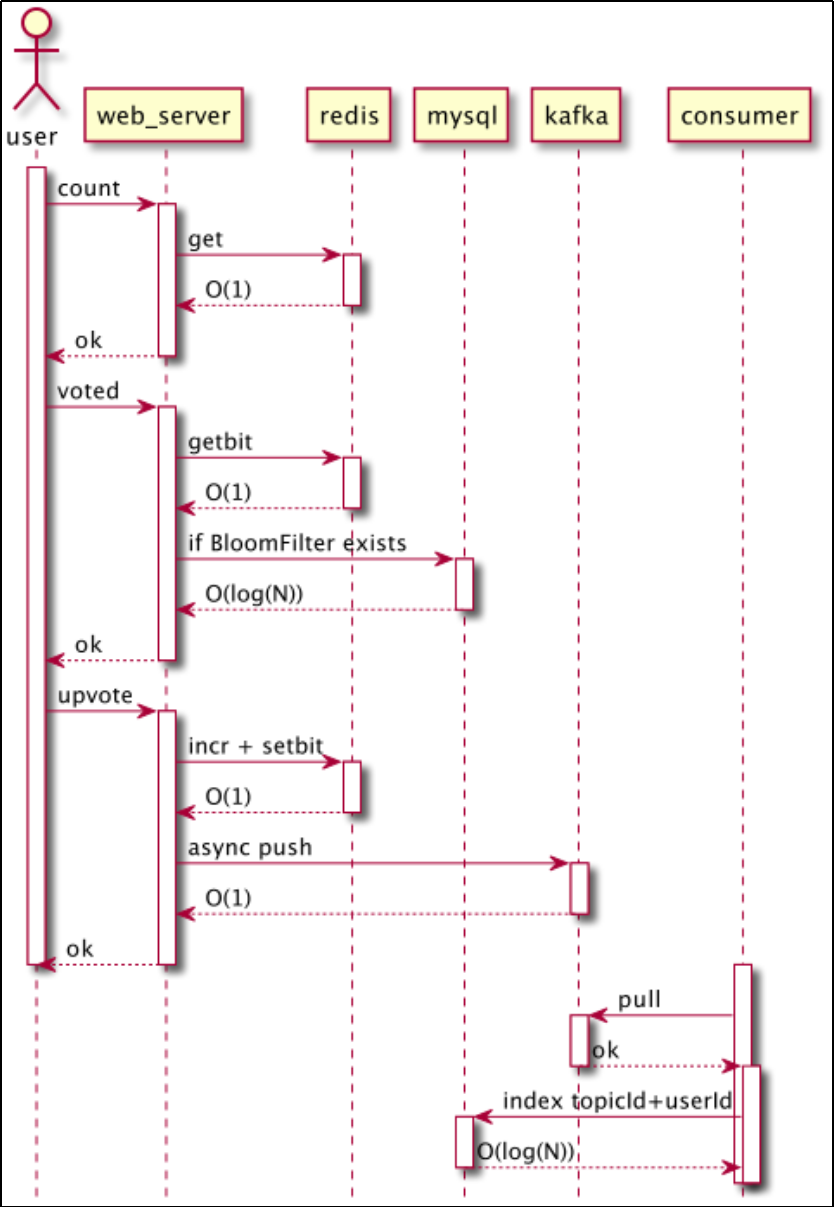
选型: Redis + Kafka + Mysql/MongoDB/HBase 基本设计
-
基于Redis string型保存点赞数目,INCR原语保证点赞数目一致性
-
基于Redis bitmap设计是否点赞bloomfilter,取消点赞需要通过counting-filter实现
-
基于Kafka实现用户行为的快速持久化,每次点赞/取消点赞都保存为一条消息
-
通过消息消费,保存用户数据到关系型数据库
-
低频操作,如查询点赞历史等,通过查询关系型数据库实现
主要业务场景实现方案
-
点赞数 get O(1)
-
是否点赞 getbit O(1) (结果为真的情况下需要查询数据库,但整体概率较低)
-
点赞/取消点赞 incr/decr + setbit + 写入消息队列 O(1)
-
查询点赞历史,利用点赞主体索引进行查询,复杂度 O(log(N) *log(M))
业务时序图
功能模块
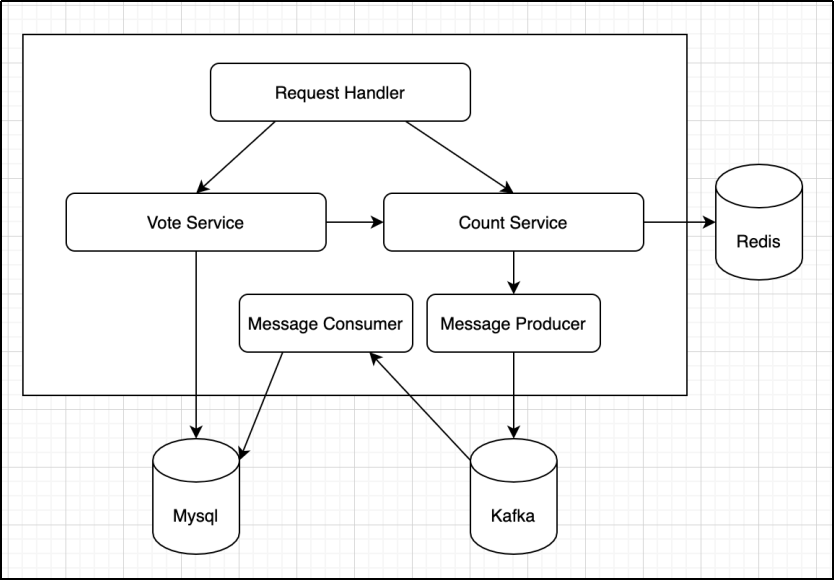
设计优势
· 兼具方案1和方案2的优点
· 消息队列弥补缓存持久性不足的缺点,同时减小了缓存与数据库文件系统间的写入效率差异
-
高可用性(并发响应)、高一致性,可以很好支持大部分ToC的业务场景
-
主要业务场景运算快速,可用性远胜于方案2
-
更低实现成本,对内存要求远低于方案1
-
整体扩展性更好
-
主要业务场景水平扩展性与方案1持平
-
低频业务场景可以选择写多读少的数据存储方案,水平扩展能力优于方案2
-
可以保存更多元数据,利于业务逻辑扩展
-
设计缺陷
-
实现较为复杂,对于多数业务场景来说存在过度设计的问题
-
业务高峰可能因为消息消费不及时带来部分数据延迟,如无法查询到点赞记录
部分实现代码
// 点赞
public boolean upvote(Upvote upvote) {
// 增加主题计数
redisTemplate.opsForValue().increment("demo.community:upvote:count" + upvote.getTopicId());
// 计算BloomFilter偏移量
int[] offsets = userHash(upvote.getUserId());
for (long offset : offsets) {
redisTemplate.opsForValue().setBit("demo.community:upvote:user:filter" + upvote.getTopicId(), offset, true);
}
// 异步发送消息
kafkaTemplate.send("demo-community-vote", gson.toJson(upvote));
return true;
}
// 是否点赞
public boolean upVoted(Upvote upvote) {
// 计算BloomFilter偏移量
int[] offsets = userHash(upvote.getUserId());
for (long offset : offsets) {
if (!Boolean.TRUE.equals(redisTemplate.opsForValue().getBit(UPVOTE_USER_FILTER_PREFIX + upvote.getTopicId(), offset))) {
// 不存在对应点赞数据,直接返回
return false;
}
}
// 不能确定点赞记录是否存在,查询数据库
return upvoteMysqlDAO.findOne(Example.of(upvote)).isPresent();
}
性能测试
硬件情况:
-
cpu intel i5 2.7GHz 4核8线程
-
memory 16G 系统和用户线程消耗 7G左右
受限于以下问题影响,测试结果仅供参考:
-
程序逻辑随机性不足,难以实际模拟真实生产数据场景
-
硬件限制,业务服务和数据库在同一个设备上,会形成资源竞争
-
实测过程中,发现用户服务对测试程序影响较大,同样的程序在不同时间执行也会存在差异
测试场景
主要测试以下四个场景:
-
1千万数据顺序写入数据库
-
1千万数据并发写入数据库
-
并发请求点赞数目1千万次
-
并发请求是否点赞1千万次
1千万数据顺序写入逻辑:
@Test
public void insert() {
long topicId = 10_000_000L;
long start = System.currentTimeMillis();
for (long userId = 1; userId < 10_000_000; userId++) {
Upvote upvote = Upvote.builder()
.topicId(topicId)
.userId(userId)
.votedAt(LocalDateTime.now())
.build();
upvoteService.upvote(upvote);
if (userId % 10_000 == 0) {
System.out.println("insert data count:" + userId);
long stop = System.currentTimeMillis();
System.out.println("time cost seconds:" + (stop - start) / 1000);
}
}
long stop = System.currentTimeMillis();
System.out.println("total time cost seconds:" + (stop - start) / 1000);
}
1千万数据并发写入逻辑:
@Test
public void insert() throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(100);
long start = System.currentTimeMillis();
AtomicInteger count = new AtomicInteger();
// 将用户分为100组,每组由1个线程顺序往10000个主题中写入数据
for (int taskId = 0; taskId < 100; taskId++) {
final int startUserId = taskId * 10 + 1;
executor.submit(() -> {
Upvote upvote = new Upvote();
upvote.setVotedAt(LocalDateTime.now());
for (long userId = startUserId; userId < startUserId + 10; userId++) {
for (long topicId = 1; topicId <= 10_000; topicId++) {
upvote.setTopicId(topicId);
upvote.setUserId(userId);
upvoteService.upvote(upvote);
count.incrementAndGet();
}
System.out.println("insert data count:" + count.get());
long stop = System.currentTimeMillis();
System.out.println("time cost seconds:" + (stop - start) / 1000);
}
});
}
// 等待任务完成,每轮检查一次任务完成情况,已完成则提前结束等待,最多等待30轮
executor.shutdown();
int waitRound = 0;
while (!executor.awaitTermination(1, TimeUnit.MINUTES) && ++waitRound < 30) {
System.out.println("wait round: " + waitRound);
}
System.out.println("insert data count:" + count.get());
long stop = System.currentTimeMillis();
System.out.println("total time cost seconds: " + (stop - start) / 1000);
}
1千万个请求 并发 查询点赞数:
@Test
public void testCount() throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(100);
long start = System.currentTimeMillis();
AtomicInteger count = new AtomicInteger();
for (int i = 0; i < 1000; i++) {
executor.submit(() -> {
for (long topicId = 1; topicId <= 10_000; topicId++) {
upvoteService.count(topicId);
int total = count.incrementAndGet();
if (total % 10000 == 0) {
long stop = System.currentTimeMillis();
System.out.println("select data count:" + total + " time cost seconds:" + (stop - start) / 1000);
}
}
});
}
executor.shutdown();
int waitRound = 0;
while (!executor.awaitTermination(1, TimeUnit.MINUTES) && ++waitRound < 30) {
System.out.println("wait round: " + waitRound);
}
long stop = System.currentTimeMillis();
System.out.println("total time cost seconds: " + (stop - start) / 1000);
}
1千万个请求 并发 查询是否点赞:
@Test
public void testVoted() throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(100);
long start = System.currentTimeMillis();
AtomicInteger count = new AtomicInteger();
for (int taskId = 0; taskId < 100; taskId++) {
final int startUserId = 20000 + taskId * 10 + 1;
executor.submit(() -> {
for (long userId = startUserId; userId < startUserId + 10; userId++) {
for (long topicId = 1; topicId <= 10_000; topicId++) {
Upvote upvote = Upvote.builder()
.topicId(topicId)
.userId(userId)
.build();
upvoteService.upVoted(upvote);
int total = count.incrementAndGet();
if (total % 10000 == 0) {
long stop = System.currentTimeMillis();
System.out.println("select data count:" + total + " time cost seconds:" + (stop - start) / 1000);
}
}
}
});
}
executor.shutdown();
int waitRound = 0;
while (!executor.awaitTermination(1, TimeUnit.MINUTES) && ++waitRound < 30) {
System.out.println("wait round: " + waitRound);
}
long stop = System.currentTimeMillis();
System.out.println("total time cost seconds: " + (stop - start) / 1000);
}
测试结果
所有场景测试结 果(qps)如下表:
| 测试场景 | ** 方案一 ** | ** 方案二 ** | ** 方案三 ** |
|---|---|---|---|
| 顺序写入 | 7000 | 700 | 2200 |
| 并发写入 | 27700 | 2100 | 5600 |
| 点赞数 | 31600 | 1500 | 33800 |
| 是否点赞 | 28500 | 1400 | 13400 |
此处的qps指每秒完成的业务单元运算次数,不是指数据库层面的一个原子操作
Redis测试情况
元素为8字节ID,socre为8字节时间戳,加上前驱后继指针共32字节,索引节点3个指针需要24字节 ZSet为跳表,检索1千万个元素需要索引节点数为 10_000_000 + 10_000_000/2 + 10_000_000/4 + … + 1 ~= 35_000_000 预计1千万条数据的内存消耗 32B 1_000_000 + 24B 35_000_000 ~= 1.2GB
顺序写入:1千万个元素插入单个ZSet内,内存消耗1.16G,耗时1488S(单线程),qps~=7000 并发写入:1千万个元素分布到1万个ZSet内,内存消耗1.06G,耗时361S(100线程),qps~=27700 查询点赞数:100个线程并发查询1千万数据,耗时316S,qps~=31600 查询是否点赞:100个线程并发查询1千万数据,耗时351S,qps~=28500
Note: 由于Redis是基于内存的高速写入操作,实测过程中并发度到10左右qps即可达到程序瓶颈,并发度提升到100并不能提升整体吞吐量,反而会降低单个任务的处理时间。
Mysql测试情况
数据:主键ID-8字节,主题ID-8字节,用户ID-8字节,行为时间-8字节,每条数据32字节,索引24字节,总计56字节。
顺序写入:1千万条数据单线程插入,执行了300万条数据,耗时4500秒,qps~=667 并发写入:1千万条数据100个线程并发插入,30分钟插入380万数据,qps~=2100 查询点赞数:查询60万数据,耗时391S,qps~=1500 查询是否点赞:查询50万数据,耗时366S,qps~=1400
Note: Mysql的写入效率远低于Redis,实测过程中需要达到50左右的并发度,才能逐渐触及瓶颈
通过Mysqladmin查看到,数据库qps约8000。
mysqladmin -uroot statusUptime: 1517 Threads: 122 Questions: 12211865 Slow queries: 0 Opens: 246 Flush tables: 3 Open tables: 167 Queries per second avg: 8050.009
数 据库的统计数据和实际运算结果呈现出来 4倍差距,这个问题后续再分析。
Redis + Kafka + Mysql 测试情况
1千万个元素,按1%的误报率构建BloomFilter,需要三个数位保存,意味着要向Redis写入三次 1万个计数器,Redis内存基本没什么消耗。
顺序写入:1千万条数据单线程写入,30分钟完成400万数据,qps~=2200 并发写入:1千万条数据并发写入,耗时1760S,qps~=5700 查询点赞数:100个线程并发查询1千万数据,耗时296S,qps~=33800 查询是否点赞:100个线程并发查询6百万数据,耗时446S,qps~=13400
Note: 对比方案一,本方案需要利用Redis存储BloomFilter,写入场景的频率增加了3倍,导致整体的吞吐量下降。从单机测试结果分析,写入瓶颈不在Kafka,而在于对布隆过滤器的多次位写入操作。如果减少布隆过滤器的写入次数,可以提升整体的吞吐效率。
通过Kafka-producer-perf-test查看写入性能,可以看到写入Kafka不是瓶颈。
kafka-producer-perf-test --topic demo-community-vote --throughput -1 --num-records 100000 --record-size 1024 --producer-props bootstrap.servers=127.0.0.1:9092
100000 records sent, 52410.901468 records/sec (51.18 MB/sec), 291.51 ms avg latency, 667.00 ms max latency, 291 ms 50th, 369 ms 95th, 398 ms 99th, 428 ms 99.9th.
接口性能测试
接口测试受到硬件影响比单元测试更大,需要考虑的配置(如合适的Web容器)也更多。使用当前硬件进行了部分测试,结果误差很大,因此这一次先按下不表。如果有机会模拟更合适的环境,再进行一次测试。
总结
基于上述测试结果,总结一下各个方案的优缺点:
| 方案 | 优点 | 缺点 | 备注 |
|---|---|---|---|
| 优先队列 | 高可用、高一致、易扩展、易实现 | 成本要求较高 | 适合数据量不高,需求不明确的场景 |
| 关系型数据库 | 高一致、强持久、低成本、易实现 | 并发度低,难水平扩展 | 适合低并发场景 |
| 缓存+消息队列+关系型数据库 | 高可用、强一致、强持久、低成本、易扩展 | 实现复杂,存在过度设计风险 | 适合高并发、数据量大、需求明确的场景 |
基于 上述优缺点,个人建议:
-
大部分业务场景,在千万级数据量级别时,可以直接选择方案一,因为实现简单,且可以向任意方案扩展
-
基础数据量较大,且增速较快,可以选择方案三,因为扩展性和一致性都更强。通常数据量的增长与并发度呈正相关,大数据量意味着高并发
-
业务系统简单,用户量在十万级别时,可以选择方案二,基本不会出现性能瓶颈。但这种情况,方案一也大概率可以覆盖
实践中,选择方案一可以满足大部分业务场景。点赞计数是一个拥有热点数据的场景,可以通过冷数据入库的方式来节约内存成本。比如三个月以前的数据可以选择从Redis中清除,持久化到数据库。在查询过程中,可以通过一个BloomFilter存储对应主体的数据是否已经持久化到关系型数据库。通过这个结果来判断访问内存还是访问关系型数据库。
实际业务中,不同场景可以有不同优化方案。比如用户对看到的点赞数、是否点赞等数据的一致性要求并不是那么高,可以通过客户端缓存等方式降低对服务端一致性的要求和访问压力。具体情况具体分析,本文的设计方案只针对服务端进行设计。
后记
技术方案设计过程中,除了进行经验评估,往往还需要在实践中来验证自己的想法。在这次测试过程中,遇到过许多与设计预期不符合的情况,如:
-
Redis内存消耗大于方案设计时的预期,原因是没考虑到跳表的索引节点开销
-
BloomFilter设计不合理,导致Redis成为写入瓶颈,原因是参数不合理,导致需要数十次Redis访问
-
受连接池配置、Web服务器配置影响,测试结果远低于预期等
这些问题都是在实践过程中遇到后,逐步分析,一个一个解决的。这些问题再次印证那一句名言:
实践是检验真理的唯一标准!
评论区